Source: Qubits
On the third day of Open Source Week, DeepSeek unveiled the “power” behind training inference V3/R1.
DeepGEMM: An FP8 GEMM (General Matrix Multiplication) library that supports dense and mixed expert (MoE) matrix multiplication operations.
Let’s start with a brief look at GEMM.
GEMM, which stands for General Matrix Multiplication, is a fundamental operation in linear algebra. It is a common operation in scientific computing, machine learning, deep learning, and many high-performance computing tasks.
But because its computational workload is often relatively large, performance optimization of GEMM is crucial.
DeepSeek’s open-sourced DeepGEMM still maintains the characteristics of “high performance + low cost”, with the following highlights:
- High Performance: On the Hopper architecture GPU, DeepGEMM can achieve performance of up to 1350+ FP8 TFLOPS.
- Simplicity: The core logic is only about 300 lines of code, but the performance is better than that of a kernel optimized by experts.
- Just-In-Time Compilation (JIT): It adopts a fully just-in-time compilation approach, which means it can dynamically generate optimized code at runtime to adapt to different hardware and matrix sizes.
- No heavy dependencies: This library is designed to be very lightweight, without complex dependencies, making deployment and use simple.
- Support for multiple matrix layouts: Supports dense matrix layout and two types of MoE layout, making it adaptable to various application scenarios, including but not limited to hybrid expert models in deep learning.
Simply put, DeepGEMM is mainly used to accelerate matrix operations in deep learning, especially in large-scale model training and inference. It is particularly suitable for scenarios that require efficient computing resources and can significantly improve computing efficiency.
Many netizens are quite “buying in” on this open source release, with some likening DeepGEMM to the superhero of the mathematical world, believing it to be faster than a lightning-quick calculator and more powerful than polynomial equations.
Others likened the release of DeepGEMM to the stabilization of quantum states to a new reality, praising its cleanliness in instant compilation.
!
Of course… some people are starting to worry about their NVIDIA stocks…
!
Learn more about DeepGEMM
DeepGEMM is a library specifically designed to achieve concise and efficient FP8 general matrix multiplication (GEMMs), with fine-grained scaling capabilities inspired by DeepSeek V3.
It can handle both general matrix multiplication and support general matrix multiplication for MoE groups.
This library is written in CUDA, and does not need to be compiled during installation, because it will compile all kernel programs at runtime through a lightweight just-in-time compilation (JIT) module.
Currently, DeepGEMM only supports NVIDIA’s Hopper Tensor Core.
In order to solve the problem that the FP8 tensor core is not accurate enough to calculate the accumulation, it adopts the two-stage accumulation (boosting) method of the CUDA core.
While DeepGEMM borrows some of the ideas from CUTLASS and CuTe, it doesn’t overrely on their templates or algebraic operations.
Instead, the library is designed succinctly, with only one core kernel function and about 300 lines of code.
This makes it a concise and easy-to-understand resource for learning FP8 matrix multiplication and optimization techniques under the Hopper architecture.
Despite its lightweight design, the performance of DeepGEMM can match or exceed expert-tuned libraries for various matrix shapes.
So how about the specific performance?
The team tested all shapes that may be used in inference with DeepSeek-V3/R1 on H800 using NVCC 12.8, including pre-padding and decoding, but without tensor parallelism.
The following figure shows the performance of ordinary DeepGEMM for dense models:
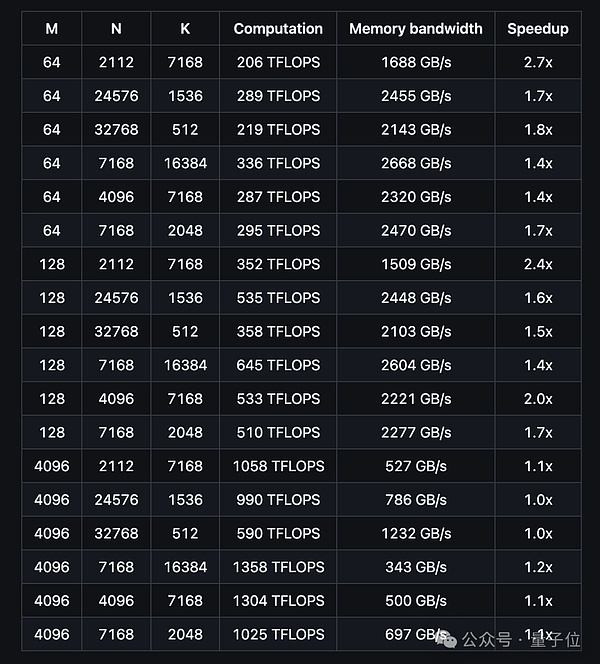
According to the test results, the DeepGEMM computing performance can reach up to 1358 TFLOPS, and the memory bandwidth can reach up to 2668 GB/s.
In terms of acceleration ratio, it can reach up to 2.7 times compared to the optimized implementation based on CUTLASS 3.6.
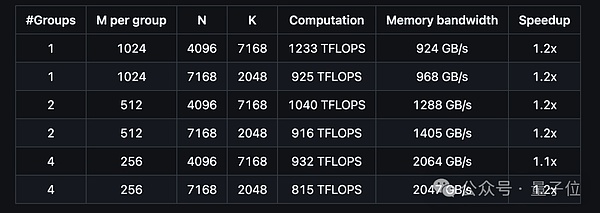
Let’s take a look at the performance of DeepGEMM to support the contiguous layout of MoE models:
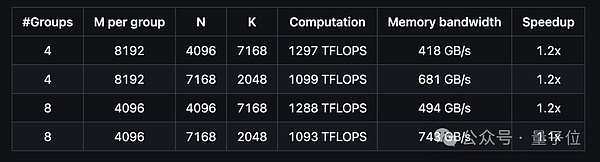
And the performance of supporting the MoE model masked layout is like this:
How to use?
To use DeepGEMM, you need to pay attention to several dependencies, including:
- Must support Hopper architecture GPU, sm_90a.
- Python 3.8 and above.
- CUDA 12.3 and above (12.8 recommended).
- PyTorch 2.1 and above.
- CUTLASS 3.6 and above
The development code is as follows:
# Submodule must be clonedgit clone --recursive [email protected]:deepseek-ai/DeepGEMM.git# Make symbolic links for third-party (CUTLASS and CuTe) include directoriespython setup.py develop# Test JIT compilationpython tests/test_jit.py# Test all GEMM implements (normal, contiguous-grouped and masked-grouped)python tests/test_core.py
The installation code is as follows:
python setup.py install
After the above steps, you can import deep_gemm into your Python project.
In terms of interfaces, for ordinary DeepGEMM, the deep_gemm.gemm_fp8_fp8_bf16_nt function can be called, and NT format (non-transposed LHS and transposed RHS) is supported.
For grouped DeepGEMMs, m_grouped_gemm_fp8_fp8_bf16_nt_contiguous in the case of continuous layout. In the case of mask layout, it is m_grouped_gemm_fp8_fp8_bf16_nt_masked.
DeepGEMM also provides tool functions for setting the maximum number of SMs, obtaining TMA alignment size, etc.; supports environment variables, such as DG_NVCC_COMPILER, DG_JIT_DEBUG, etc.
In addition to this, the DeepSeek team offers several ways to optimize, including:
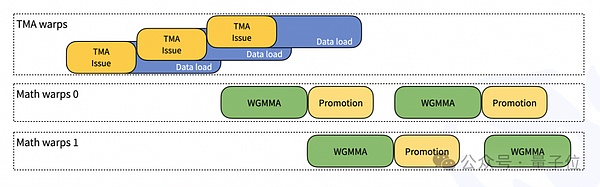
JIT Design: All kernels are compiled at runtime, no need to compile at installation time; Supports dynamic selection of the optimal block size and pipeline stage.
- Fine-grained Scaling : Solving the FP8 precision problem through two-layer accumulation of CUDA cores; supporting non-power-of-two block sizes to optimize SM utilization.
- FFMA SASS Interleave : Improve performance by modifying the yield and reuse bits of SASS instructions.
Interested friends can click on the GitHub link at the end of the article to view the details~
One More Thing
Nvidia’s stock … these days Well… Keep falling again:
!
However, in the early hours of the 27th Beijing time, Nvidia’s performance report for the fourth quarter of FY2025 is also about to be released. Let’s look forward to its performance~