在 AI 产业中,数据始终是决定模型性能的核心资源。随着大模型进入精细化训练阶段,单纯依赖大规模数据已难以持续提升性能,高质量、可验证的数据逐渐成为关键。然而,传统数据标注体系在激励机制与数据可信度方面存在结构性不足,这为新型数据经济模型提供了发展空间。
Perle 正是在这一背景下提出,通过 Web3 重构数据生产与价值分配模式。相较于传统由中心化平台主导的数据体系,Perle 将贡献记录、激励分配与数据管线迁移至链上,试图解决数据不透明、参与者议价能力弱以及激励不可持续等问题。在这一体系中,PRL 是驱动整个数据经济网络运转的核心媒介。
Perle 项目简介
Perle 可以被理解为“面向企业级 AI 的链上数据协调层”,其目标是构建一套以人类参与为核心、具备可验证性与可追溯性的数据生产基础设施。在这一体系中,企业或开发者可以提出具体的数据需求,由全球分布的标注者与审核者完成任务,并通过链上记录确保每一次贡献都能够被追踪与审计。
从技术架构来看,Perle 通常依托高性能公链(如 Solana)作为结算与归属层,同时围绕数据生产流程构建任务分发、结果提交、质量验证与信誉积累等模块。值得注意的是,PRL 并不承担底层共识或 gas 支付功能,而是专注于“人类参与层”的经济协调,用于激励贡献者并对齐生态各方的长期利益。
PRL 代币的核心功能
根据目前公开信息,PRL 在 Perle 经济体系中主要承担以下几类核心功能:
-
激励与奖励:PRL 用于奖励完成数据标注、审核和质量提升任务的贡献者,激励真实、持续、高质量的人工参与。
-
访问与参与:在企业或机构侧,PRL 有望被用于访问特定数据产品、参与高级功能或在未来的治理与资源分配中获得权重。
-
协调与治理:PRL 被定位为“协调层代币”,用于对齐基金会、投资人、团队和社区在长期生态建设上的决策与收益分配,这使得其经济设计更侧重参与激励与治理,而非共识安全。
从整体定位来看,PRL 更接近一种“协调型代币”,其核心作用在于连接供需双方,并在长期推动生态治理与资源配置,而非承担底层网络安全职能。

PRL 代币分配结构
根据公开信息,PRL 总供应量为 10 亿枚,主要在社区、生态、投资者与团队之间进行分配。这一结构体现出明显的“生态优先”导向,即通过较高比例的社区与生态分配来推动网络早期增长。
其中,社区部分占比最大,并在较长周期内逐步释放,用于空投、任务激励与用户增长;生态基金则用于支持合作伙伴、产品开发与市场拓展。相比之下,投资者与团队份额通常附带更长的锁仓与线性解锁机制,以降低短期抛压并强化长期绑定。
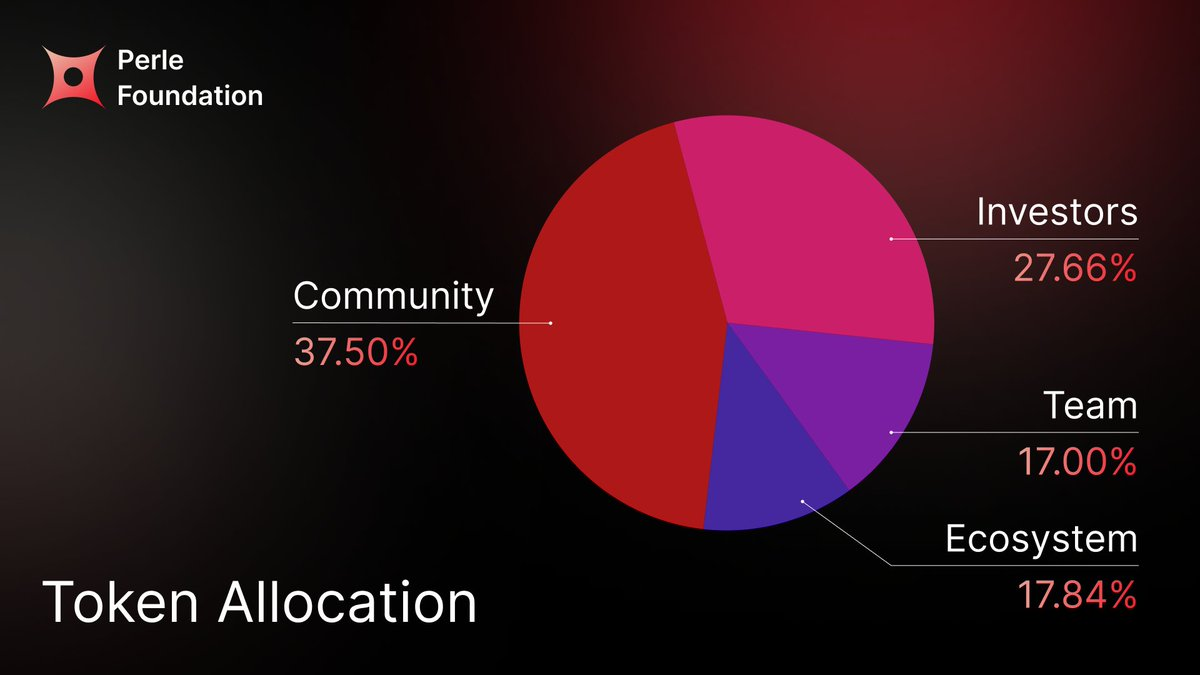
具体来看:
-
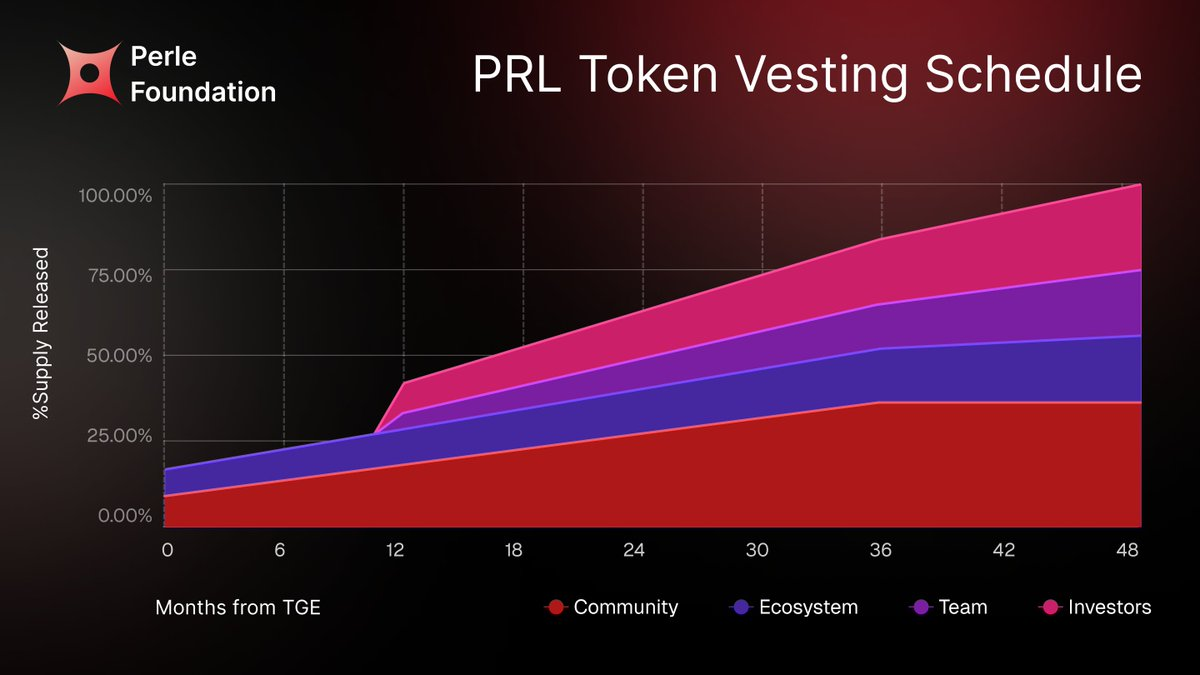
社区(37.5%):在 TGE 时先解锁 7.5%,其余部分在 36 个月内线性释放,用于空投、任务激励和其他社区参与奖励。
-
生态发展(17.84%):约 10% 在 TGE 时解锁,用于启动生态与合作,其余部分在 48 个月内线性释放,支持产品开发、合作项目和市场拓展。
-
投资者(27.66%):设置 12 个月崖期(cliff),之后在 36 个月内线性解锁,降低早期集中抛压的风险。
-
团队(17%):同样采取 12 个月崖期加 36 个月线性释放,以强化核心贡献者的长期绑定。
整体来看,这种分配方式有助于在早期释放足够激励以吸引参与者,同时通过长期释放机制平滑供给压力。但随着时间推移,市场仍需持续吸收新增流通,这对真实需求提出了更高要求。
PRL 激励机制设计
PRL 的激励机制围绕“数据贡献—质量验证—价值反馈”展开,其核心在于通过经济手段提升数据质量。
贡献者通过完成标注、审核或纠错任务获得 PRL 奖励,而奖励额度通常与任务难度及完成质量相关。这种设计鼓励参与者优先投入高价值任务,而非追求数量扩张。
与此同时,Perle 引入链上信誉体系,用于区分长期稳定贡献者与短期参与者。高信誉账户在任务分配与奖励权重上通常更具优势,从而在一定程度上抑制低质量数据与“刷任务”行为。
在需求侧,企业通过使用平台数据或服务,为代币体系带来实际需求。如果这一需求能够持续增长,将与供给侧激励形成正向循环。
PRL 的价值捕获路径
从设计初衷来看,PRL 的价值捕获逻辑并非来自“底层 gas 费”或“质押收益”,而是来自“成为数据经济的协调与访问层”。
-
访问与使用层:企业在访问特定数据产品或高级功能时,可能需要持有或使用 PRL,从而构成对代币的结构性需求。
-
治理与资源分配:随着网络发展,PRL 可能用于治理决策或资源配置(如生态基金、参数调整等),使得持币不仅意味着潜在经济收益,还代表在网络方向上的一定话语权。
-
声誉与激励叠加:对贡献者来说,持续高质量参与既能获得 PRL 奖励,也能积累链上声誉;在长期,这种“声誉 + 代币”的组合有机会转化为接更多高价值任务或参与更高层决策的资格。
因此,PRL 的价值捕获本质上取决于数据需求的增长以及网络使用规模的扩大。
Perle 代币经济模型的飞轮效应
Perle 团队与外部投资机构都强调了一个“飞轮”式逻辑:越多高质量人类参与、越多企业在平台上消费数据,网络越有价值,PRL 的经济模型越有可能良性运转。
这一飞轮可以拆解为:
-
通过 PRL 激励吸引贡献者参与任务,积累高质量、可审计的数据集。
-
高质量数据吸引企业和开发者采用 Perle 作为数据获取与评估渠道。
-
企业侧的需求为网络带来实际收入或价值,从而为 PRL 的使用、回购、抵押或治理提供空间。
-
如果部分价值回流到激励池或生态基金,则可以进一步提高任务奖励,吸引更多高质量参与者加入。
这一过程形成一个自增强循环,使数据质量、需求规模与代币价值相互促进。
PRL 的潜在风险与挑战
尽管整体设计具有一定逻辑闭环,但 PRL 仍面临多方面不确定性。
首先,长期解锁机制意味着持续的代币供给,如果需求增长不足,可能带来价格压力。其次,企业端采用速度仍存在不确定性,若真实使用场景未能形成,代币价值捕获将受到限制。
此外,激励机制需要在短期收益与长期参与之间取得平衡,否则可能出现“挖提卖”等行为,从而削弱生态稳定性。专家供给的稀缺性也是潜在瓶颈,因为高质量数据难以通过简单扩张获得。
最后,监管与合规环境同样可能影响其发展,尤其是在跨区域数据与加密激励结合的背景下。
总结
PRL 作为 Perle 网络的核心代币,其设计重点在于通过激励机制与治理结构,将人类高质量数据贡献转化为可持续的经济行为。通过以社区与生态为导向的分配模式,以及围绕数据生产构建的激励体系,Perle 试图建立一个连接数据供需双方的长期价值网络。
从长期来看,Perle 成功与否将取决于两个关键因素:一是能否持续吸引高质量数据供给,二是能否形成稳定增长的企业端需求。一旦供需两侧形成正循环,PRL 才有可能实现真正的价值捕获。
FAQs
PRL 代币的主要用途是什么?
用于激励数据贡献者,并作为 AI 数据交易的支付媒介。
PRL 如何捕获价值?
通过 AI 企业购买数据形成实际需求,从而支撑代币使用。
PRL 的激励机制有何特点?
强调数据质量,并结合审核与声誉系统进行分配。
PRL 是否具备长期价值?
取决于数据需求增长与生态使用情况。
PRL 面临的最大风险是什么?
主要包括需求不足、激励失衡以及代币通胀压力。
作者: Jayne
译者: Jared
审校: Ida
免责声明
* 投资有风险,入市须谨慎。本文不作为 Gate 提供的投资理财建议或其他任何类型的建议。
* 在未提及 Gate 的情况下,复制、传播或抄袭本文将违反《版权法》,Gate 有权追究其法律责任。
分享


Sign Up
相关文章

新手
不可不知的比特币减半及其重要性
在比特币网络历史上,最令人期待的事件之一就是比特币减半。当矿工验证交易并添加新区块后获得奖励时,就会创建新的比特币。新铸造的比特币就是奖励的来源。比特币减半减少了矿工的奖励,因此新比特币进入流通的速度也减半。人们认为减半事件对网络以及比特币的价格产生了重大影响。
法币何时发行取决于政府的决定,而比特币则不同,其发行上限为21,000,000枚。减半是一种调节比特币产量的方法,同时有助于抑制通货膨胀,因为减半让比特币的铸造无法超过发行量上限。本文将深入研究比特币减半及其重要性。
2022-12-14 05:48:29

新手
如何选择比特币钱包?
本文将介绍一些最通用的比特币钱包类型,还将研究每种钱包的优缺点,以及它们的功能、安全性和易用性。阅读完本文,您能更好地了解可用的不同类型的比特币钱包,并明白哪一种更适合您。
2026-03-24 11:52:27


中级
Master Protocol:激活 BTC 生息潜力
比特币的工作量证明限制了持有者通过直接质押的方式获得收益,尽管比特币在市值上驱动主导机制地位,但大量比特币未充分利用。通过主协议协议,用户可以将比特币质押在第 2 层上,并接收 LST 作为其质押凭证,允许用户在多个场景下再次投资他们的 LST,在不影响流动性的情况下保证收益,透视对再质押协议的采用,用户可以进一步质押LST连接LRT,再次增强他们的投资能力和资产流动性。
2024-07-08 16:45:06

中级
CKB:闪电网络促新局,落地场景需发力
在最新发布的闪电网络Fiber Network轻皮书中,CKB介绍了其对传统BTC闪电网络的若干技术改进。Fiber实现了资产在通道内直接转移,采用PTLC技术提高隐私性,解决了BTC闪电网络中多跳路径的隐私问题。
2024-09-10 07:19:58

中级
Solana 将成为下一个爆点
本文深入分析了 Solana 的技术优势,例如高 TPS、低交易成本和快速终结性,并且阐述了其在稳定币流动性及代币化资产规模方面的强劲增长。
2026-03-24 11:57:52