比 FTX 崩盘更令人恐惧:本周比特币你需要了解的 5 件事
ForesightNews
BTC-0.18%



作者:NCL
编辑:Siqi
排版:Mengxi

• 片间互联是下一代计算中心的关键技术路径,它通过砍除传统架构下的复杂网络功能来实现更高性能,同时也为资源池化提供了性能保证,从物理硬件层来实现计算资源的按需分配成为可能;
• 硅光子技术则利用成熟的芯片工艺大规模量产光子收发器,显著提升了元件密度和成本优势;
• Chiplet 是被 AMD 和 Apple 验证的芯片架构层的突破。为片间通讯提供了合理的产品形态,允许计算芯片和互联芯片高效互联,有助于降低芯片间互联的延迟和能耗。
Ayar Labs 因站在这三项新兴技术的交叉点上而进入到我们的视野之中:Ayar Labs 是一家将硅光子学运用于片间通讯的芯片公司,在 2015 年由 4 位 MIT 学生共同创立,近期估值已接近 10 亿美元。Ayar Labs 的产品从硬件层面上实现了对现有主流技术 1-2 个数量级的提升,其产品出色的性能也吸引了包括了 Intel、NVIDIA 和 HPE 等行业内的重要公司的投资支持,并且在后几轮融资中仅接受半导体行业内公司的战略投资。
不过,虽然 Ayar Labs 在最为激进的技术路径上已经拥有成熟产品,但它所处的商业生态至少还需要 5 年时间才能完全爆发,这让 Ayar Labs 的商业化处境尴尬。对于 Ayar Labs 而言,在生态成熟前独立运营需要面临商业化上挣扎,但其过硬的产品让芯片巨头收购成为一个保底退路。**基于 Ayar Labs 的研究,我们也认为,****如果要在片间通讯领域进行投资布局,**当下并不是最好的 timing,需要在 2025-2027 年左右重新评估市场的主流技术路线和竞争格局。
**以下为本文目录,**建议结合要点进行针对性阅读。
👇
01 Thesis
02 背景
03 产品
04 市场策略及生态
05 团队
06 市场估算
07 竞争
08 风险和争议
01.
Thesis
1. 片间通讯将成为下一代计算中心的关键技术路径:
NVIDIA 已通过 NVLINK 证明片间互联能大幅提升算力的可扩展性(增效),而 Intel 和 AMD 正在尝试用 CXL 实现资源池化后对计算中心进行极致的成本管控(降本)。两种路径都将需要硬件层面的能耗、带宽和延迟表现有 1-3 个数量级的提升,硅光子学和互联 Chiplet 两个技术的组合将能成为突破瓶颈的关键。
2. Ayar Labs 是一家用硅光子技术制造互联 Chiplet 的公司,其产品在硬件层面能提供比现有主流技术 1-2 个数量级的提升:
Ayar Labs 的光信号互联芯片的面积带宽密度 (单位是 Gbps/mm2)是主流设备的 20 倍,延迟和能耗却只需要主流设备的 1/30 和 1/3 左右,并且产品在 2022 年已初步实现量产,其产品出色的性能吸引了 Intel 和 NVIDIA 的密切关注、以及多轮投资作为支持。
3. 我们对于公司最大的顾虑是公司商业化,因为成熟的硬件产品在没有合适的软件生态下难以形成竞争力:
我们预估无论是 NVLINK 转向硅光技术还是 CXL 生态成熟都需要五年左右的时间周期,在这之前公司都只能配合各大芯片公司做内部研发,难在近期把产品优势转化成长期生态优势。
4 尽管 Ayar Labs 的产品竞争力和成熟度都极高,但相对于硬件固有的冗长迭代时间,则成为了一个生不逢时的“硅光之星”:
尽管自身产品竞争力和成熟度极高,但芯片领域高度集中的客户群体和硬件固有的冗长迭代时间,使得公司几年内难以转动庞大的生态飞轮,相对于持续独立发展,对于 Ayar 来说,就算公司商业化受挫而难以支撑,NVIDIA 或 Intel 很有可能会愿意为了公司技术 IP 和团队而进行收购。
02.
背景
**LLM 浪潮除了带来软件革命,也在给硬件层的计算中心带来巨变,我们预计计算中心将会在 5 年内被重构:**一方面,相较于传统软件,LLM 带来了远超于过去规模的训练数据集,对算力的可扩展性提出了极高要求;另一方面,Capex 视角下,这些变化让计算资源和设备等硬件成本迅速上升,因而对于科技公司而言,给计算中心降本增效也是参与到 LLM 之中的关键动作。而片间互联、硅光子和 Chiplet 三者技术的组合所提供的新的计算中心架构,让降本增效变得可行。
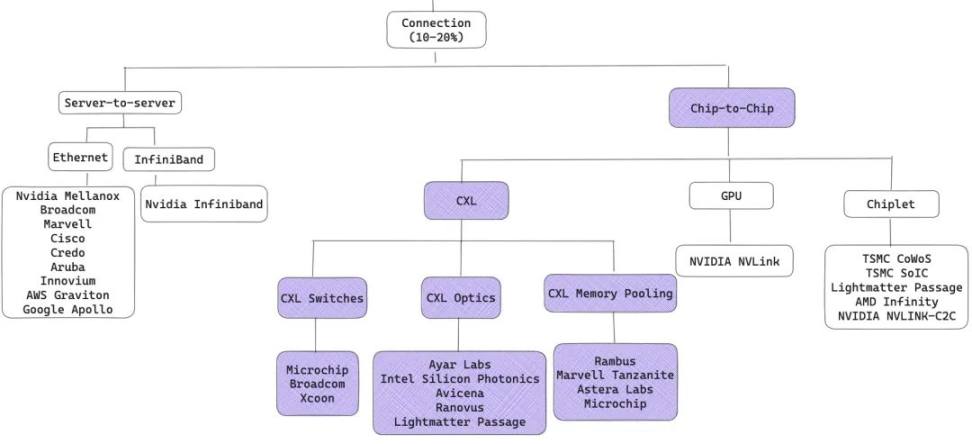
片间互联:
下一代计算中心的关键技术路径
片间互联(Chip-to-Chip)正成为下一代计算中心的关键技术路径。
LLM 热潮带来对算力需求的升级,算力的可扩展性(Scalability)也成为芯片公司的重要竞争指标,NVIDIA 凭借 NVLINK 在模型训练市场占据了领先优势,也驱动计算中心的互联架构从 Server-to-Server 转向 Chip-to-Chip 。
NVLINK 是 NVIDIA 推出的一种 GPU 间高速互连技术,它的革新之处在于绕过了传统 Ethernet(/Infiniband)的 Server-to-Server 互联架构,转而鼓励 GPU 之间直接通讯,为此,NVIDIA 还推出了片间通讯交换机 NVSwitch。
NVLINK 协议之所能比传统 Ethernet 协议更快,根本原因是砍掉了 Server-to-Server 架构下的复杂网络功能(例如端到端重试、自适应路由和数据包重新排序等),并将 CUDA 和 NVLINK 协议结合后实现了极高带宽和能耗的互联性能。技术层面,NVIDIA 对传统网络架构下几乎每一个协议都做了增删填改(如下图),从而让 Chip-to-Chip 的性能上限超越了同代的 Server-to-Server。
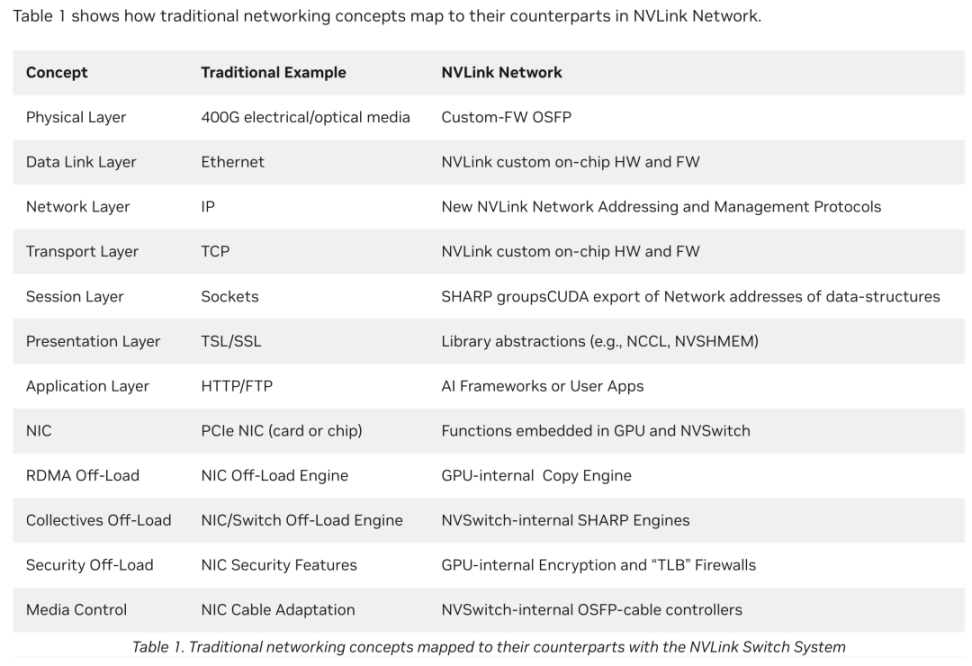
**我们可以把 NVLINK 的算力的可扩展性(Scalability)定义为从“增效”层面满足科技公司算力需求的升级, Intel 和 AMD 则是从“降本”的角度出发:**数倍上升的大规模训练数据集和强大算力需求带来倍数上升的计算资源和硬件需求,在 Capex 视角下,硬件成本也会对计算中心规模带来重大影响。站在企业角度,就要考虑如何对这部分成本进行优化。
传统的服务器架构下,云计算公司需要大幅提前预判客户需求、分配资源,但在实际运营中,计算中心内的需求是复杂多样的,于是就会发生计算资源错配和浪费。为了提高计算资源的利用率,芯片和云计算巨头提出了将芯片、内存、硬盘池化,从而让客户自己能够按需购买,即“资源池化”,资源池化是对物理资源计算资源的粒度化和池化,为更低成本的云计算提供了物理基础。
💡
资源池化又可以分为内存池化和硬盘池化。我们可以通过 Azure 内存池化后的例子来看资源池化带来的成本优势。Azure 的内存预算占到了 Azure 服务器成本的 50%,Azure 研发团队尝试用现有、相对早期的内存池化技术搭建了内存池 Pond,尽管内存的读写延迟是平常的 2-3 倍,但是这套系统将所需的 DRAM 成本压低了 10%,也就是节省下了总硬件成本的 5%。这项技术仍在极早期,未来有望在成本和延迟上有进一步的降低。
在 2019 年,Intel 和 AMD 还提出了 CXL (Compute Express Link),CXL 的主要作用是让各个计算机部件(计算芯片、内存、硬盘和互联设备等)之间进行高速数据传输,让它们更好的协同工作,将服务器的每一个部件都分解并池化,CXL 的最终愿景是在计算中心里替代以太网(Ethernet),侧重于 Chip-to-Chip 的通讯,并且可以提供极高带宽和较低延迟。
硅光子学:
计算中心“最后一米”的最优解
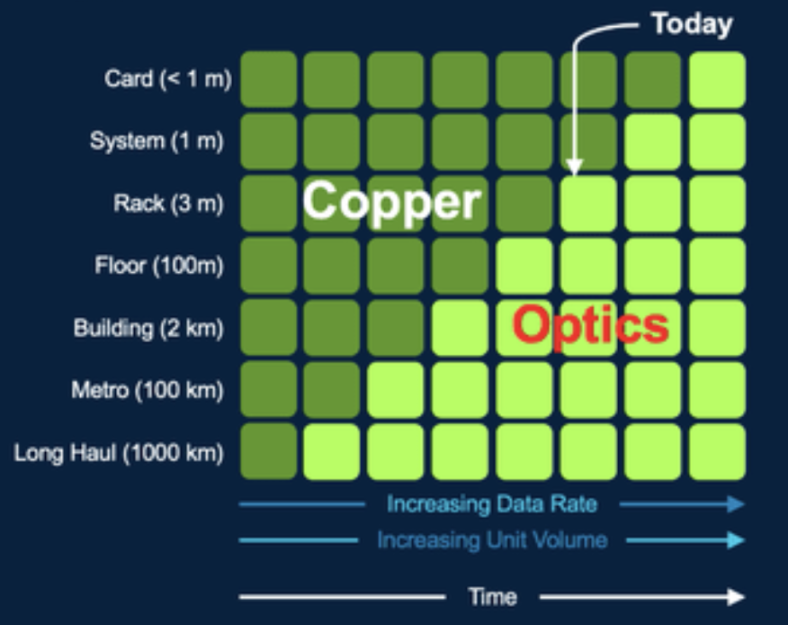
**由于能耗、扩展和迭代成本等问题,芯片和云计算巨头们普遍认为,如果要将计算中心的能力再扩展三个数量级,放弃铜缆网线、转向光纤是一个必然选择。**从上世纪 90 年代开始,光纤已经被部署在较长距离的海底光缆和城际光缆中,随着设备体积和性能的优化,目前 3 米以上的通讯距离都已经大规模采用光缆而不是铜线了。
💡
传统铜揽电线和光纤的性能表现差异:
**• 能耗:**铜缆的能耗通常是是光纤的 5 倍左右,下一代数据中心的高性能铜缆网线每传输 1 bit 的数据需要 20-30 pJ 的电量,而光缆则能做到 1-10 pJ 之间;
**• 可拓展性:**铜缆的最大互联距离是光纤的 1/100 左右。用铜线传输信息时,会因电阻的影响而受到信号的衰减和畸变。高性能铜缆网线的最大传输距离不超过小几十米,而光缆可以轻松支持 1 公里以上的距离,这显然意味着更强的算力扩展能力;
**• 迭代成本:**传统的数据中心互联网络每隔 2-3 年就要更换为更高性能的交换机,而谷歌内部自建光缆交换机 Jupiter 则能减少交换机的更新频率,从而每年为 GCP 节省下 30% 的硬件运营成本。
**凭借能耗和可扩展性优势,光学元件(Optics)已经在数据中心的 Server-to-Server 互联进行渗透。诸多芯片和云计算巨头也基本转向 Optics 设备来改善服务器集群的能耗比:**例如 Meta 的 VP of Infra 就透露 Meta 内部的 AI 训练服务器集群已基本采用 Optics,在 NVIDIA 的设计中,有望在 NVLINK 6.0-7.0 时实现从电信号向光信号的转化。
Chip-to-Chip 互联环节同样存在光学元件替换传统铜线通讯的需求,但对 Optics 的体积和成本提出了更进一步的要求,硅光子学的成熟成功解决了这部分问题,预计会成为 Chip-to-Chip 互联的主流解决方案。

目前主流的光互联部件的形态为可插拔光模组(Pluggable Optics)。传统的可插拔光模组设计中涉及到大量的电和光元件(如下图示例),且部分元件的制作过程中还需要磷化铟和砷化镓等小众材料,实际生产中就会牵涉到不同的供应商,繁多的工艺和材料首先会导致产品成本高企,此外,这些部件之间依然使用电路板上的铜线通讯,所以最终产品从尺寸、性能和成本在短期内难以有较大突破。并且,由于每个部件的市场空间较小、涉及到的产业参与方众多,产品工艺制程的迭代也被拉慢。
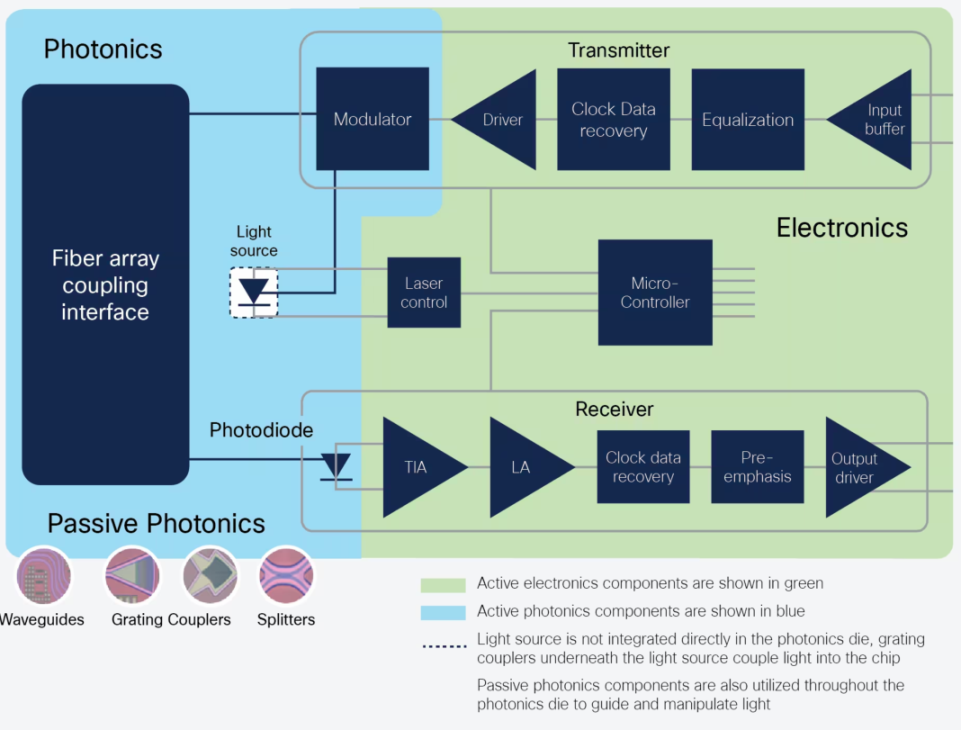
**Intel 力推的硅光子(Silicon Photonics)技术就是对可插拔光模组(Pluggable Optics)从工艺层面的改良。**硅光子学技术简单说就是用硅片来构建光子收发器里的所有组件。不仅从原材料角度对传统设计中的不同元件材料进行替代、整合,制作上也复用了成熟的 CPU 制造工艺,这些都有效降低了光模块(Optical Module)的成本。


整个收发器功能都包含在一个单一的芯片组中。
**硅光子可插拔光学模组的升级替代不仅在于成本层面,它最大的价值在于满足片间通讯对收发器的密度和性能需求。**传统可插拔光学模组解决的是 Floors/Racks/s 之间(> 1m)的光互联问题,但片间通讯(Card/Die,< 1m)对光子收发器的密度和性能要求更高,更短距离的互联需要进一步提升光子收发器的密度,从而部署在体积较小的显卡或是加速卡上,硅光子学的成熟让光子收发器的体积压缩从制作上成为可能,随着 Chiplet 技术的萌发,硅光子收发器更是能被直接安装在 Card/Die 旁,硅光子学模块有望在未来几年内渗透到这个计算中心的最后一米。
Chiplet:
为片间互联提供可行的产品形态
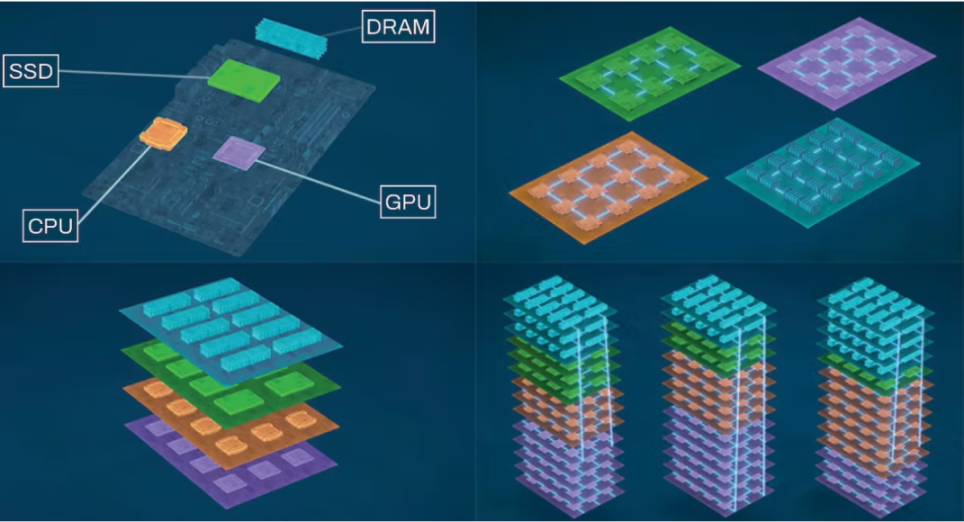
**Chiplet 是近年来芯片设计最重要的技术路径突破,简单来说就是像 Lego 积木一样堆叠芯片,**Chiplet 可以让芯片公司根据需求自己设计如何堆叠摆放多个芯片,再交由 TSMC 制造,比如 Apple 的 M1 Ultra 芯片就是依靠 Chiplet 技术将两块 M1 MAX 结合在一起。
在 Apple 和 AMD 前瞻地选择这一技术路径后取得巨大成功后,Chiplet 现在已成为芯片设计行业的主流技术路径。Chiplet 技术的成熟也为 Chip-to-Chip 互联设备提供了合理的产品形态,同时也解决了资源池化对传统架构下芯片到互联设备提出的带宽、延迟和能耗问题。
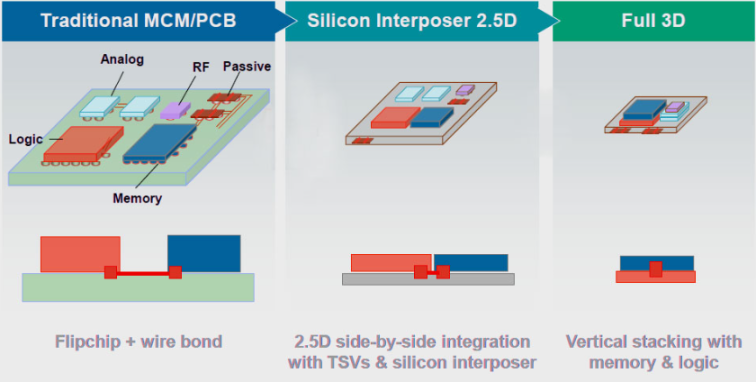
在过去,芯片(CPU、GPU 和内存)之间的通信依靠主板中埋设的铜线进行,芯片数量的增加就意味着需要设计更大的主板以支持更多芯片的互联,尽管在设计层面可以实现,但芯片之间通讯带宽、延迟和能耗已逐渐成为瓶颈。于是,TSMC 和 AMD 等芯片巨头提出以 Silicon Interposer 作为通讯介质, 从而拉近芯片之间的距离(如下方中图),甚至更近一步,允许芯片之间的堆叠(如下方右图),即 Chiplet,从而带来显著的全方位性能提升。Silicon Interposer 就是芯片堆叠过程中的“Lego 卡扣”。
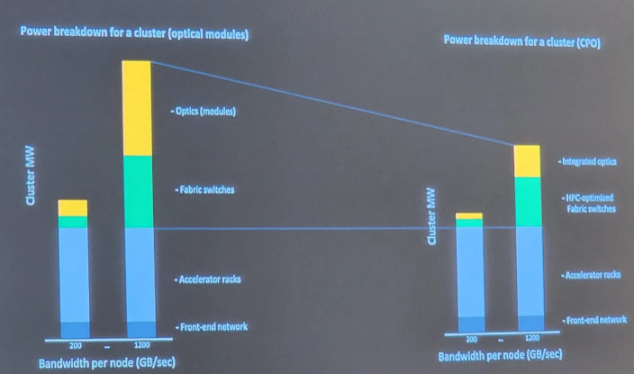
**Chiplet 同样也能够被运用到互联设备的设计上,从而提升互联设备的性能上限。**Meta 的 VP of Infrastructure Hardware Alexis Black Bjorlin 分享过其内部 AI 服务器集群的现状:尽管他们的互联设备已从铜缆转向光缆,但是他们担心随着传输性能从 200GB/s 提升到 1200 GB/s 时,耗电量占比将从 10% 提升到 70%,互联设备的耗电量将远超现在最强超算的耗电量,也因此他们打算用 In-package/Co-package Optics(将在后文介绍) 解决这个问题,即将光互联设备缩小后,用 Chiplet 技术紧密地放在计算芯片旁边,从而改善互联性能、能耗和延迟问题。
与互联设备相连,但带宽和能耗也将成为瓶颈。
03.
产品
Ayar Labs 就是结合了硅光子和 Chiplet 设计新一代片间互联产品。Ayar Labs 的产品可以拆分为两部分:
**1. TeraPHY:**光信号互联芯片,负责处理光电信号,完成信号之间的转换和收发;
**2. SuperNova:**独立激光器,负责精准地发出多个波长的光子。
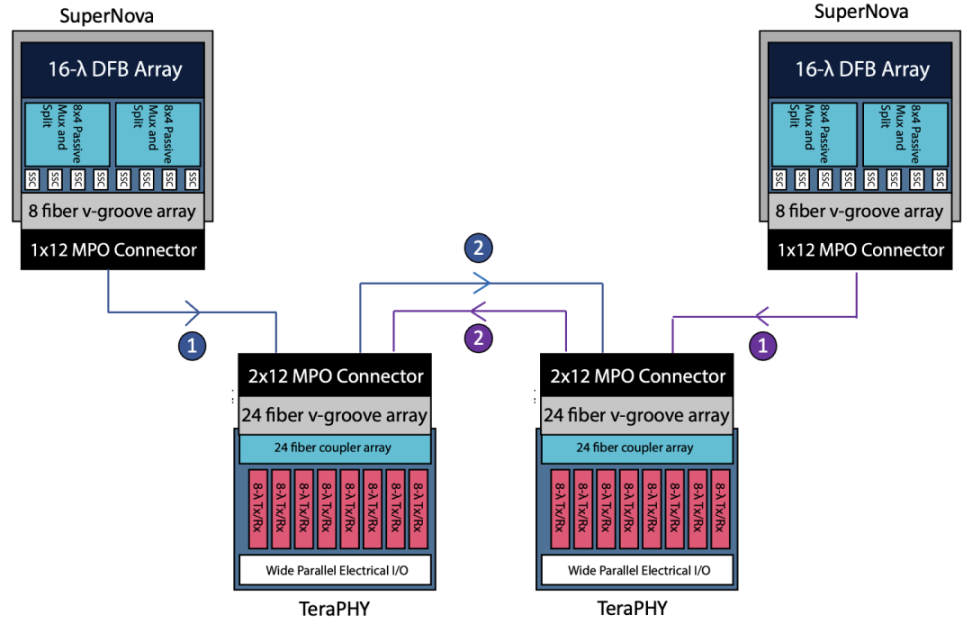
在具体实践中,SuperNova 需要和 TeraPHY 组合使用,二者通常以下图中的链路互联:
💡
-
SuperNova 稳定从 8 个 SCC 打出激光束,每个激光束包含 8 个不同波长的激光,但此时还不包含信息。换言之, ① 中是不包含信息的 8 个纯激光束。
-
TeraPHY 同时从 Electrical IO 接收来自芯片的电信号,以及从 SuperNova 中来的纯激光,其内部的 Optical Transceiver 则将电信号转换成光信号,再通过 ② 传输到另一个 TeraPHY 芯片上。 ② 中也有 8 个激光束,每个激光束有 8 个波长的激光,每个激光最高能带 25Gbps 的信息,也就是最多能传输 8×8×25 = 1.6 Tbps 的信息。
-
另一个 TeraPHY 接收到 ② 的信号后,内部的 Optical Transceiver 中能将光信号转化成电信号,再通过 Eletrical IO 告诉芯片信息,从而完成通讯。
* Ayar Labs 在 2023 OFC 宣布了新版 TeraPHY 支持每个激光最高能带 32 Gbps 的信息,也就是最多能有 8×8×32 = 2.048 Tbps 的通讯速率。
TeraPHY
TeraPHY 是一个光信号互联芯片(Optical I/O Chiplet),用来实现光电信号之间的转换和收发,也要负责中间信号的各种转化运算。TeraPHY 是 Ayar Labs 先进的电路设计能力的体现:在 Ayar Labs 的设计下,**除了激光外的部件都能够设计到一个极小的芯片里,芯片的元件密度被大幅提升。**具体来说,TeraPHY 的芯片里包含了以下几个模块:
**• Grating Coupler Fiber Coupling Array:**这是光信号的输入输出模块。每 3 个尖触(是 Grating Coupler)为一组,每一组最左边的是接受端,另外两个是发送端,总计有 10 组;
**• Optical Transceiver:**主要负责进行光电信号的双向转换,这里主要由微环调制器(Micro-ring Modulators)和微环滤波器(Micro-ring Filter)组成,前者负责调制出所需的光信号,后者负责处理接受的光信号,把不同波长的信号分离开,再转化成电信号传给 AIB;
**• Glue/Crossbar:**是 Optical Transceiver 和 AIB 之间的连接桥梁;
**• AIB:**负责和芯片之间的电信号互联。

**TeraPHY 的面积带宽密度(Area Bandwidth Density,单位是 Gbps/mm2)是现在主流设备的 20 倍左右:**TeraPHY 能够只用用 75mm2 大小的芯片实现 2 Tbp/s 的数据交换处理,而当前大部分铜缆和光缆模组需要 150mm2 的芯片处理 0.2 Tbp/s 的数据交换。NVIDIA 首席科学家 Bill Dally 持续数年追踪 Ayar Labs 在一些半导体会议上的演示,并经常提出各种挑战性问题以确保对方没有作弊,因为他难以想象这是怎么做到的。
TeraPHY 同样在降低能耗和延迟上表现出色,比典型光学设备有 1-2 个数量级上的比较优势:当前 TeraPHY 的能耗是 Pluggable Optics 的 1/3,是 NVLINK 2.0 的 1/2。此外,由于使用了 Chiplet 的路径和计算芯片的紧密结合,单芯片延迟低至 5 ns,是 Pluggable Optics 的 1/30-1/20 左右,也是 NVLINK 2.0 的 1/40 左右,这样的数据已经低于 DDR4/HBM 内存的延迟,能够初步满足内存池化的要求。

with Fast Interconnects
**TeraPHY 的核心壁垒在于微环调制器的设计和制造上:**首先,微环调制器的效果极易受温度影响,所以在微环调制器周围必须设计升温电路;此外,由于光信号在 nm 级的尺度下容易不稳定,会出现信号出错的情况。Ayar Labs 方面曾宣布这些问题在其制造合作方 GlobalFoundries 的共同研发下都已经被解决,从而让 15-100°C 的温度下给出准确波长的光信号成为可能。
💡
GlobalFoundries 是一家总部位于美国的半导体制造公司,成立于 2009 年,起初为 AMD 公司的制造部门,后来成为独立公司。GlobalFoundries 是全球最大的独立晶圆代工厂之一,提供先进的半导体制造解决方案。
GlobalFoundries 在全球拥有多个先进的晶圆代工厂,包括位于美国、德国和新加坡等地的制造工厂。该公司拥有广泛的制造技术和工艺平台,包括 14 纳米、12 纳米、7 纳米和 5 纳米等先进工艺。此外,GlobalFoundries 还提供多种封装和测试服务,以支持客户的完整芯片解决方案。
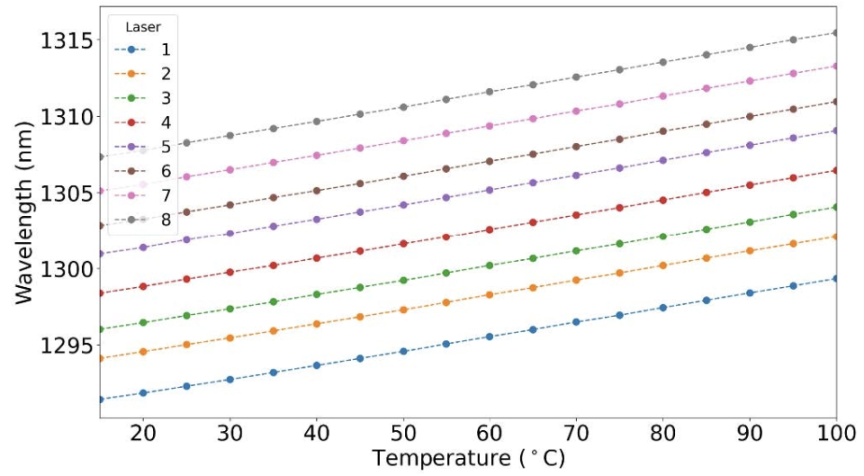
考虑到日益增长的互联需求,TeraPHY 也已经开始向支持多种扩展方案的方向迭代:
• 目前每个 TeraPHY 理论上能有 2Tbps 的带宽,但考虑到随着芯片制程进步能在相同面积下放入更多的处理设备,目前 Ayar Labs 的产品路线图中已经有 4、8 Tbps 的版本;
• 随着 Chiplet 技术的成熟,未来的芯片面积也将显著增大,比如 Jensen Huang 在发布 NVLINK Chip-to-Chip 时曾表示 NVIDIA 将长期探索如何将芯片面积尽量做大,这意味着能在芯片周围放入更多的 TeraPHY(当前工程样品为 4 个);
• 由于 Chiplet 正在从 2D 逐渐转向 3D,未来 TeraPHY 也还可以堆叠起来(就像 HBM 内存是 DDR 内存的堆叠),这又是一种增加总带宽的扩展方法。

SuperNova
SuperNova 是独立的激光器,负责准确地发出多个波长的光子。在实际应用中,SuperNova 需要和 TeraPHY 配合使用。
**SuperNova 的存在有它的时代背景:**在 Ayar Labs 创办初期,硅光子学还没有成熟到能把激光器做到芯片里,所以激光器只能作为独立部件存在。2022 年 9 月,Intel Labs 发布了集成在芯片里的激光器,虽然这一产品还在实验室阶段,但独立激光器的必要性确实已经成为一个市场争论点,我们也会在后文的竞争部分详细讨论。
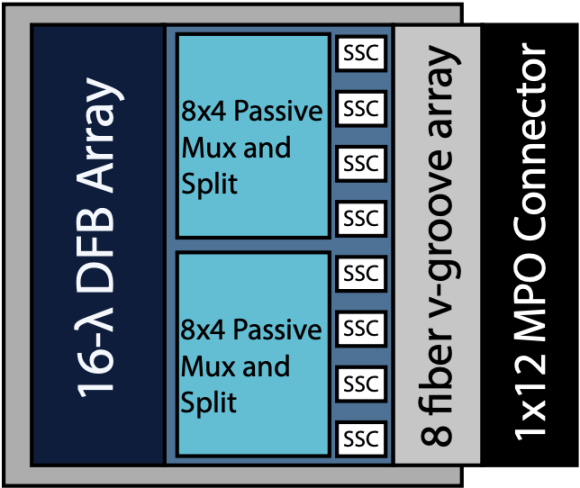
SuperNova 由 Ayar Labs 和 MACOM 联合设计,交由 UK 知名激光制造商 Sivers Photonics 制造。一个 SuperNova 的具体结构包括:
• 16-λ DFB(Distributed Feedback) Array: 这是和 Macom (DFB 的顶尖设计商之一)合作设计的高性能激光器阵列,支持同时发出两组 8 个不同波长的激光;
**• Passive Mux and Split:**MUX 负责把多个波长的光线合束到单一通道中,Split 则负责将这个光信号分发到每个 SSC (输出端口)中。可以看到这里分为上下两个 Mux 和 Split,每组处理 8 个不同波长的光信号,所以每个 SCC 有 8 个不同波长的光信号;
**• SSC:**输出端口,总共有 8 个,每个端口支持同时输出 8 个波长的光信号;
**• Fiber V-Groove Array:**光纤阵列,这里将 SCC 中分配好的光用光纤连接器与外界相连;
**• MPO Connector:**是插光纤的连接口。
技术路径
市面上光模块的产品形态有三类,分别是 Pluggable Optics,Co-Package Optics 和 In-Package Optics,Pluggable Optics 是当下最主流的方案,而 Ayar Labs 所选择的 In-package Optics 路线最为激进、但同时性能也最强大:
Pluggable Optics
• 插卡式的独立光模块,通过接口连接到设备插槽上;
• Pluggable Optics 需要通过 Substrate 和 Board 两个介质中的铜线来和计算芯片通信,在延迟和带宽上限制明显。

Co-package Optics(CPO)
• 将多颗芯片使用 Co-packaging 技术整合在一个基板上,光模块也集成其中;
• 光模块与计算芯片靠近,但仍需通过 Substrate 中的铜线传输信号、和计算芯片通信。

In-package Optics(IPO)
• In-package Optics 直接参考了 Chiplet ,把计算芯片和光模块共封装在一个封装体内,通过“Lego 卡扣” Silicon Interposer 连接,Silicon Interposer 同时也被作为传输介质和计算芯片进行互联通信;
• IPO 通过采用硅互连,跳过传统铜线,彻底解放了光模块的性能极限,在带宽、能耗和延迟和 Pluggable Optics、CPO 两个仍需要使用铜线的方案比有极大的优势。

**In-package Optics 相较于前面两个方案放弃了灵活性而追求极致性能,Ayar Labs 正是利用 In-package Optics 的技术优势,力求打造性能先进的光模块产品。**Ayar Labs 的首席架构师 Vladimir Stojanovic 详细比较过 CPO 和 IPO 两个方案的差异,他认为 IPO 的带宽上限为 CPO 的 5 倍,延迟为 CPO 的 1/20,能耗方面二者则十分接近。和 Co-package 、 Pluggable Optics 相比,In-package Optics 更符合它们的技术目标。而交换机厂商目前倾向于采用 Co-package Optics 改造当前的交换机,也可能是因为它们没有在 In-package 的技术积累。
04.
市场策略及生态
From IP to Chiplet
**在公司成立初期 Chiplet 技术并没有被主流市场认同,所以 Ayar Labs 和其他芯片公司一样,通过将设计专利(IP)授权给芯片厂进行商业化。**通过 IP 授权,Intel、AMD 这些芯片厂可以在设计芯片时有权使用 Ayar Labs 设计的电路,但是 Ayar Labs 的 TeraPHY 采用 45nm 生产,这跟 NVIDIA 或 Intel 最先进的芯片制程相差较远(≤ 7nm),这些光学元件的成本和稳定性问题会让计算芯片厂难以接受。
💡
互联设备的芯片制程通常比顶尖 CPU、GPU 的制程更落后,这是因为网络设备厂商、云计算厂商等在互联设备的预算并没有芯片预算这么高,而落后制程意味着更低的制造成本、更高的良品率。此外,光子会在 5nm 左右的硅片中波长会不稳定,导致信号丢失,也就是说,即便 Ayar Labs 目前在 45nm 解决了稳定性问题,但并不能保证在 5nm 时不会出现。
**Chiplet 的出现则显著增强了公司产品的适用性和市场空间。**Chiplet 技术允许 Intel 或 Nvidia 在其 ≤5nm 芯片和 Ayar Labs 的 45nm 芯片高效互联,这样就允许客户轻松将 TeraPHY 设计到自己的最新产品中,也让 Ayar Labs 自己掌控产品更新周期,并且将产品价格控制在合理范围内。
搭建生态
Chiplet 给了硅光子学产品一个完美的 Go-to-Market 方式,也让 Ayar Labs 有机会引导仍在萌芽的硅光子产业,确保自己产品始终处于生态的一部分则是 Ayar Labs 目前最重视的战略,Ayar Labs 选择引入产业上下游厂商的战略投资,以此模糊合作和竞争的边界。
Ayar Labs 的投资人中不仅有上游的芯片制造商 Applied Materials 和 GlobalFoundries,也有下游的 Nvidia、Intel 和 HP Enterprise 等产业巨头。其中, Intel、HPE 和 NVIDIA 中任意一家都有足够的产品需求量级让 Ayar Labs 茁壮成长,也间接将 Intel 这样的直接竞对化为合作客户。Ayar Labs 的 CEO 透露,公司和 NVIDIA 的投资协议中就包含共同研发的议题,他们将帮助 NVIDIA 的产品逐渐转向硅光子技术。
尽管目前 Ayar Labs 目前行业内产品化最领先的公司,但是 Intel 的行业地位和技术积累需要让公司担心目前的产品是否有持续的竞争力,考虑到 Intel 完全有动力和能力复刻一个类似 NVLINK 的封闭生态。为钳制 Intel 开发闭门生态,Ayar Labs 花费了巨大的精力来编写和推广 CW-WDW MSA 标准,以鼓励上下游公司围绕相同的标准建立生态系统。
💡
CW-WDM MSA ,全称为 Continuous-Wave Wavelength Division Multiplexing Multi-Source Agreement。当前的硅光子学产品都会采用多个波长的激光,这个标准规定了每一个波长的光信号应该传输哪些信息,从而让不同公司的产品之间兼容性更好。
协议的主要成员不仅包括上游的激光设计制造商(Macom、Sivers Photonics)和光学元件制造商(Sumitomo Electric),还包括关键的竞争对手 Intel,以及下游的交换机制造商(Arista)。在 CW-WDM MSA 成为行业通用标准的前提下,即使 Intel 想要转向封闭生态,它仍需要花费大量时间重新与上下游公司协调新的协议和产品,除了时间成本外,在此期间 AMD 和 NVIDIA 也有可能趁 Intel 不备来主导市场,这些都推高了 Intel 的决策成本,留给 Ayar Labs 更多发展时间。

05.
团队
Ayar Labs 创办于 2015 年 5 月,最初由四位 MIT 的学生创办:其中 Mark Wade、Chen Sun 和 Vladimir Stojanovic 三人当时都是 MIT 电子工程的 PHD 或访问学者,他们目前分别是公司的 CTO、Chief Scientist 和 Chief Architect,随后他们找到了当时在读 MIT MBA 的 Alex Wright Gladstein 加入,来担任公司的 CEO 角色。
**Mark 、Chen 和 Vladimir 这三位技术联创的核心科研成果令人瞩目,**其核心科研成果 *(Single-chip microprocessor that communicates directly using light)*目前有 1100 多个引用量,而 Mark 和 Sun 的年龄只有 36 岁,是年轻学者中的佼佼者。此外,担任 Chief Architect 的 Vladimir Stojanovic 个人总引用量为 1.4 万左右,是 UCB EECS 系的明星教授。
但客观来说,Ayar Labs 的**顶尖学者资源和整体学者规模仍逊于 Intel 的硅光子科研中心,**Intel 硅光子部门的巨擘 John Bowers 的总引用量高达 67000,Ming C.Wu 的总引用量为 27600。从绝对数量上 Ayar Labs 距离 Intel 还有一定距离,但从单篇作品来看,John Bowers 的作品论文中引用量最多的约为 1500 次引用。
目前,团队正处于从技术导向转向生产和市场导向的阶段,也因此从 Intel 和 Marvell 请来了多位重要生产和 GTM 高管。
2018 年,Charles Wuischpard 加入。作为当时 Intel 的 VP of Datacenter,Charles 被邀请加入 Ayar Labs 代替 Alex Wright Gladstein 任 CEO,希望他能将公司的技术转化成可盈利的产品。Wuischpard 利用自己在 Intel 积累的资源推动了早期 Ayar 和 Intel 合作的一些测试芯片,率先让行业看到 Ayar 较为成熟的产品。
Ayar Labs 的管理层在 2022 年有较大的变动,大幅增强了产品、营销和生产部门,以落实产品在 23 年大规模走向市场的计划:
**• Lakshmikant Bhupathi :**曾在 Marvell 工作了 20 年,他有着资深的计算中心互联设备的产品和营销经验,试图推动公司产品 2023 年全面走向市场和建设生态的计划;
**• Scott Clark :**曾在 Cosair 担任供应链 VP,负责生产和运营环节的 VP;
**• Terry Thorn:**在 Intel 负责 Datacenter Sales 24 年的 Terry Thorn 也在 21 年加入,现在主导商业化落地方向。
06.
市场估算
In-Package Optics 的客户群体主要分为 3 类:
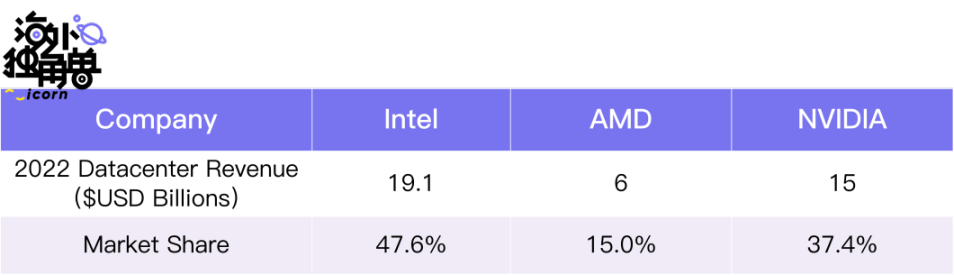
**1. 计算芯片公司:**在该领域,**Ayar Labs 和 Intel 的 TAM 份额差不多,但是 Intel 因可以完全吃下自己的份额而更占优势。**按照三大芯片公司的 Datacenter Segment 收入来推测,在最坏情况下,Intel 会和 Ayar Labs 直接竞争,Ayar Labs 则有机会拿到 AMD 和 NVIDA 侧的 50% 左右的市场份额,但前提是 Ayar 的产品在性能、成本等角度可以满足客户需求。
**2. 云计算公司:****Ayar Labs 在云计算公司更占优势。**云计算公司的自研芯片对 Intel 芯片有替代关系,所以它们双方合作开发芯片时都会心存芥蒂。此外,Ayar Labs 作为初创公司将更能灵活的配合这些云计算巨头的需求,比如 HPE 就已经和 Ayar Labs 展开合作,探索资源池化的计算中心。
**3. 交换机公司:****交换机公司大多喜欢自研或收购,Intel 因有 Pluggable Optics 时期积累的客群更占优势。**思科先后买了多家硅光子公司,所以不太可能成为 Intel 或 Ayar Labs 的客户。而 Intel 因有 Pluggable Optics 时期积累的客群更占优势。
即便 Ayar Labs 在最为激进的技术路线上实现了高水平的产品设计,但由于片间互联市场刚处于萌芽生态, Ayar Labs 的产品并不能拥有 First-Mover 的优势,距离公司大规模商业化也还有 2-4 年的周期。
我们在产品部分详细介绍了 Ayar Labs 在技术路径上所选取的 In-package Optics,公司在发展路径上也选取了最激进的 CXL 生态,但无论是技术路线还是 CXL 生态,都至少要在 4 年后将使得公司相对的产品难以在未来 2027-2028 前不会大规模铺开,可能会在 2029 年后才迎来迅猛增长,我们接下来会结合 Yole Group 的研究来估算 Ayar Labs 未来的市场空间。
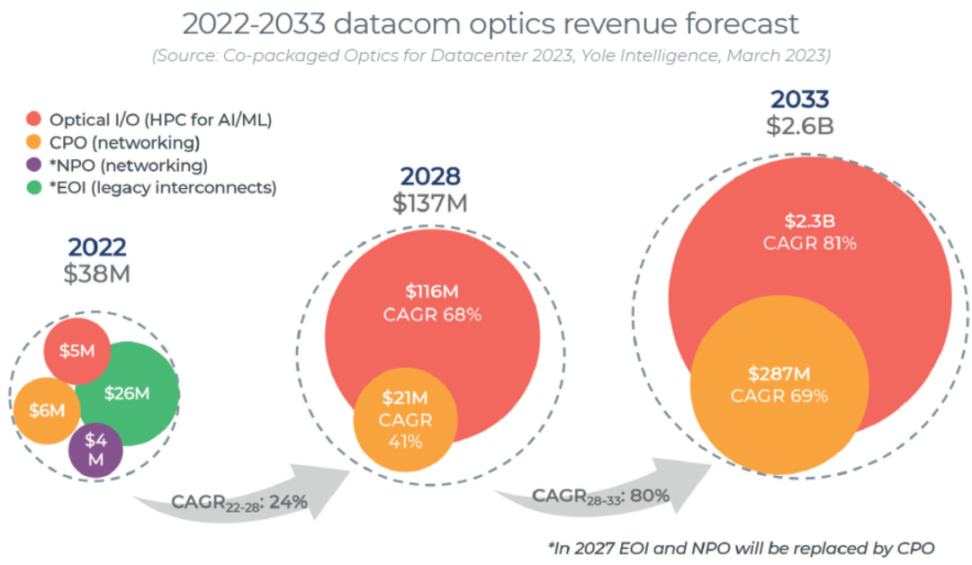
在 In-package Optics 大规模铺开前,2028 年之前 IPO 的需求大多来自芯片或交换机厂购买后在内部新产品上进行测试:In-package Optics 在 2028 年的市场份额预计只有 1.37 亿美元,其中 1.16 亿可能来自计算芯片公司(如 NVIDIA 和 AMD)研发光片间互联的研发预算,也会有 0.21 亿美元来自交换机厂商用来研发下一代交换机:
**• 传统的 Pluggable Optics 在至少未来两代产品中仍有充分的竞争力。**因为 Pluggable Optics 在完全不需要对现在计算架构更改的前提下,就能通过替代铜缆来大幅改善 Server-to-Server 的互联能耗和带宽性能。在传统互联需求下延迟指标并不关键,只有 AI 或 CXL 的持续火热才会催迫时间线的提前;
**• CXL 3.0 在 2026-2027 年才开始铺开,CXL 配套软件则需另外 3-4 年以上改善使用效率。**CXL 3.0 被视为资源池化的关键协议,而 CXL3.0 预计在 2026-2027 年才会陆续出现,在这之前都将是行业早期的小打小闹。在硬件出现后,才会有工程师围绕 CXL 撰写配套软件,预计再需要 3-4 年才能让新架构下的硬件使用效率变得有竞争力;
**• NVLINK 预计会在 6.0-7.0 才会切换为 In-package Optics,而其他公司目前没有类似的布局。**预计 NVLINK 会在未来两三代后切换成 In-package Optics,相当于在 2026-2028 年才会实现。尽管我们认为 AMD、GCP 和 AWS 的自研芯片也有极强的动力采用,但是目前还未看到相关公开信息。
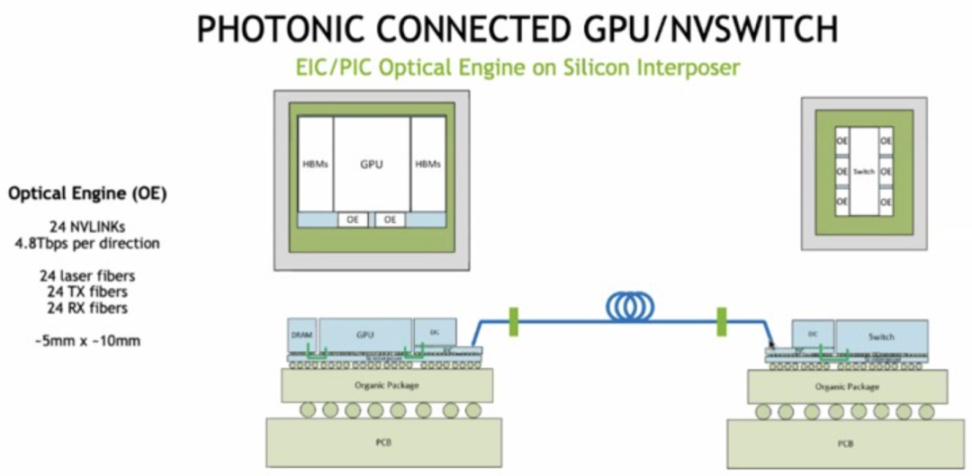
虽然从技术和产品层面,TeraPHY 在技术和产品成熟度在 In-package Optics 中是最高的,但其在 2022 年仅生产了 5000 片左右,核心原因在于需求侧,下游计算芯片厂并没有成熟的生态让他们从 Pluggable 切换到 In-package Optics。
**2029 年后,In-Package Optics 将会迎来高速增长期,参考 Yole Group 的数据,估计在 2029-2033 年间市场将以 80% CAGR 迅猛增长到 26 亿美元左右,其中 23 亿美元将会用在 AI 的计算集群中,3 亿美元会花在下一代交换机上。**我们整体比较认同这个观点,因为 CXL 的成熟和 AI 芯片的整合都将在那个时间点兑现,所以我们认为在 2025-2027 年间重点关注 In-Package Optics 公司才是合理的时机。
07.
竞争
我们整理了 CPO 及 IPO 的主要玩家,以及他们的上下游供应链的情况:
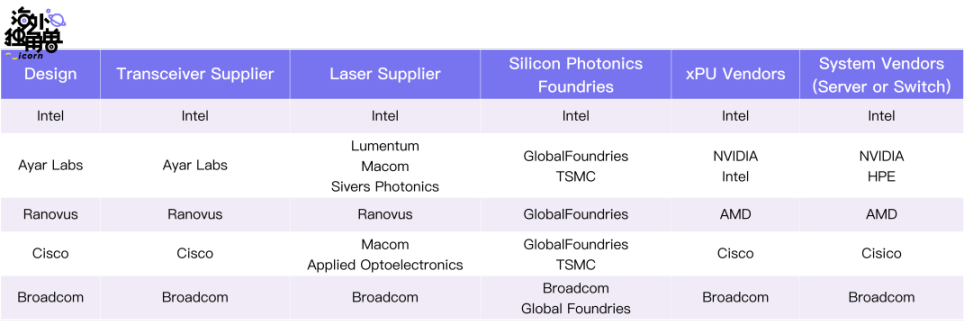
整体上因为这个领域属于刚刚萌芽的状态,Ayar Labs 这类已经有成熟产品的团队为极少数。Ayar Labs 的竞争对手主要是 Intel 和 Ranovus,Intel 是因为有完整的闭环能力、Ranovus 则是因为从上下游、产业支持方来看和 Ayar 的配置最为接近。
我们认为 Ayar Labs 在技术和产品成熟度上远领先于 Ranovus,但是和 Intel 产品相比优势并不明显,对于 Ayar Labs 来说,当下还有不错的时间窗口和 Bargaining Power 来构建生态,在这一过程中,Ayar Labs 和 NVIDIA 的关系将至关重要。
Intel
Intel 将是 Ayar Labs 最有威胁的竞争对手。Intel 不仅拥有业界最大的光子学团队,还拥有全球最好的制造工厂之一。
Intel 是硅光子产业的长期领先者,不仅在过去的十几年里积累了学界和工业界的大量人才,也在近些年逐渐重视 Co-package 和 In-package 光子收发器的未来潜力,甚至专门设立了硅光子学研究院来吸引行业顶尖人才。此外,Intel 目前占可插拔硅光子收发器 60% 的市场份额,他们也有自己极为成熟的芯片制造厂,有着明显的规模优势。
Ayar Labs 和 Intel 在硅光子学产品领域的主要区别在于产品设计和研发生产模式上。
**• 激光器独立设计:**我们在前面提到,Ayar Labs 的设计中,激光器 SuperNova 被单独分拆出来,这主要是由技术成熟度的时点导致的(在早期,芯片内置激光器的技术不成熟,尤其是温度会让激光器的性能不稳定,激光器的热度也会对散热设备有极大要求)。2022 年 6 月,Intel 宣布了内置激光器的光子收发器芯片(仍处实验室阶段),其展示的偏差数据证明已经初步攻克了内置激光器的技术难点,后续需要对生产和量产的可行性进行优化。
💡
**Ayar Labs 的 CEO 认为激光器是否独立只是一个 trade-off,并不代表技术层面的全面领先,**这一点也可以从需求侧的到验证。**Meta 和 Microsoft 曾表示偏好独立激光器:**首先,从效果上,激光器在外部或内部并不会显著影响传输的速率、延迟和能耗,如果考虑到激光器是光子收发器里最容易坏的部件,那么外部激光器的显著优势就在于可以多次更换,而内部激光器的好处是进一步压缩了光子收发器的面积和组装复杂度。
**• 研发生产能力:**如上文所提到的,Intel 拥有世界上最大的硅光子学团队和制造工厂。未来,Intel 可以使用其现有的晶圆工厂生产硅光子学芯片,这将确保产能和成本优势。Ayar Labs 的 TeraPHY 由 GlobalFoundries 负责生产,而 SuperNova 则与 Macom 基本上是合作设计,交给 Sivers Photonics 生产。显然,Intel 可以利用自己的闭环生态在最大程度上压低成本、保证良品率等。
Ranovus
Ranovus 是另一家明星硅光子初创公司,于 2012 年在加拿大创立。由于创立的更早,所以 Ranovus 的产品并没有考虑到 Chiplet 技术,和 Ayar Labs 存在一些技术路径上的差异。此外,Ranovus 很注重和 AMD 的合作,并更偏好 Ethernet 生态,所以在发展路径上也有一定差异。具体来说,它们有以下两点区别:
**• Co-package VS In-Package Optics:**Ranovus 的技术主要倾向于 Co-package Optics,尽管短期内能更低门槛地给客户安装,但是理论带宽、能耗和延迟远不如 In-package Optics。
**• 生态伙伴:Ranovus 最大的合作伙伴是 AMD,而 Ayar Labs 则与 Intel 和 NVIDIA 有不少技术版权和产品上的合作。**AMD 没有在互联设备方面有太多的投资,所以预计 Ranovus 会成为 AMD 的深度合作伙伴,甚至是潜在收购对象。Intel 因为有自己庞大的光子学部门,对 Ayar Labs 的技术依赖并没有这么深。
**Ranovus 的一部分目标市场是和交换机厂商合作,延用 Server-to-Server 的 Ethernet 生态。**这样能够保证公司在近些年有足够的订单,不用等 CXL 生态的成熟。但是目前的交换机厂商都在自研 Co-package Optics,并没有合作成功的消息,所以这一路径抉择的效果并不明显。
08.
风险和争议
未来技术路径的不确定性
Ayar Labs 选择的技术路径存在不确定性,主要体现在三个方面:
1. Pluggable Optics 不仅不会被立即替代,反而会在很长一段时间继续存在:
无论是 Co-package 还是 Ayar Labs 所采用的 In-package Optics 的互联方式,这两个方案路线的目标都是利用自身在延迟、能耗和带宽层面的表现替代当前一部分 Pluggable Optics 的市场,虽然 Pluggable Optics 的确在性能维度表现逊色,但在灵活性、互操作性、可扩展性和生态等方面有明显优势,所以 Pluggable Optics 不仅不会被立即替代,反而将在很长一段时间继续存在。在最理想情况下,Pluggable Optics 将只被用在用户的远程访问(如 SSH),而 In-package/Co-package Optics 将成为多台 Server 之间的互联方式。
2. CPO 和 IPO 的路线之争:
尽管 Co-package Optics 在可扩展性、灵活性和生产简易性上占据优势,但是仍有用户会为了极致的带宽上限和延迟性能选择 In-package Optics。
3. 内置和外置激光器:
Intel 成功研发出了拥有内置激光器的硅光子收发器,这让客户在使用时可以便捷地安装在芯片旁,不用考虑在电路板上设计外置激光器的位置。不过 Ayar Labs 的外置激光器则允许用户方便地替换易坏的激光器,也降低了对控温装置的要求。
产品表现争议
TeraPHY 的面积带宽密度和延迟数据存在着统计口径上的争议,这会进一步导致市场重新审视 Ayar Labs 的产品表现。
Ayar Labs 在宣传其产品在面积带宽密度的优势时,实际上只考虑了 TeraPHY 的面积,但在实际应用中, 独立激光器 SuperNova 显然也会占用面积,而 SuperNova 的面积并没有被纳入计算口径。
**另一方面,尽管 TeraPHY 的延迟数据很亮眼,单芯片只需要 5nm,但是目前未考虑协议延迟。**经过专家咨询,TeraPHY 理论上可以支持 Ethernet、CXL 甚至是 NVLINK,但是在运行 Ethernet 协议时延迟较高,所以 TeraPHY 在 CXL 、甚至 NVLINK 协议下,延迟数据可能难以保持亮眼的表现。
商业化困境
拥有领先的技术优势却受困于商业化是 Ayar Labs 的尴尬处境。
IPO 想要替代的 Pluggable Optics 采用的是 Ethernet 和 Infiniband 两个数十年的互联协议,但其主要能满足 Server-to-Server 互联需求,对于 Ayar Labs 这种 Chip-to-Chip 并不合适。专注于 Chip-to-Chip 互联的 CXL 则在 19 年才提出,其中预计真正能初步合理改造计算中心的 CXL3.0 协议在 22 年 8 月发布,既然 AMD Genoa 和 Intel Sapphire 在 23 年初才初步支持 CXL 1.1,那么 CXL3.0 在计算中心的铺开预计要在 2026 年实现。
**在硬件的初步 Ready 的基础上还需要数年软件生态的培育,这将进一步推迟 CXL 的 Mass Adoption。**资源池化将颠覆传统的服务器架构,这意味着开发者将需要依照新硬件架构编写新的 Complier/Package,不成熟的软件将导致较低的运行效率,可能会有较多批评的声音使得大多数开发者对于是否采用新架构而犹豫不决。
来自内存厂商的抵抗
**和计算芯片厂不同的是,内存厂商对 CXL 基本持抗拒态度。**因为 Intel 和 AMD 可以依赖 CXL 复刻 NVLINK 后增强竞争力,而内存厂商则因内存池化后需求骤降,行业里所有人都知道内存的利用效率较低,CXL 将促使计算中心把内存预算转向互联预算。
制程迭代周期过长
TeraPHY 由三位技术联创在 2015 年的论文中就用上了 45nm,8 年来公司初步解决了量产和市场等问题。但是目前公司还没证明在更先进的制程中,光信号的稳定能否不受影响,从而保持面积带宽密度优势。
Reference
1. 内存池 Pond
_Pond_asplos23_official_asplos_version.pdf
2 谷歌内部自建光缆交换机 Jupiter
3. Yole Group







免责声明:本页面信息可能来自第三方,不代表 Gate 的观点或意见。页面显示的内容仅供参考,不构成任何财务、投资或法律建议。Gate 对信息的准确性、完整性不作保证,对因使用本信息而产生的任何损失不承担责任。虚拟资产投资属高风险行为,价格波动剧烈,您可能损失全部投资本金。请充分了解相关风险,并根据自身财务状况和风险承受能力谨慎决策。具体内容详见声明。
评论
0/400
暂无评论