Las blockchains tradicionales suelen considerar los datos como un elemento secundario y separan el almacenamiento de la ejecución. Esta arquitectura dificulta que las aplicaciones on-chain utilicen datos a gran escala y aumenta la dependencia de servicios externos. Irys resuelve este reto integrando almacenamiento de datos, verificación y ejecución en un único framework.
Para entender Irys, es fundamental conocer el ciclo de vida completo de los datos: cómo se suben, se verifican en la red y se utilizan o consultan. El mecanismo de almacenamiento por particiones y minería (Partition Lifecycle) es clave para comprender su verificabilidad.
Principios fundamentales del almacenamiento de datos en Irys: capa de datos descentralizada y almacenamiento verificable
Irys emplea una arquitectura Datachain, integrando los datos directamente en el consenso de la blockchain. A diferencia del almacenamiento tradicional, los datos no solo se conservan: se convierten en un estado on-chain verificable.
En este modelo, cada dato debe ser confirmado por la red como realmente presente y accesible. Así, los datos dejan de ser un elemento pasivo y pasan a tener existencia comprobable, lo que refuerza la confianza en el sistema.
Además, Irys integra los datos con su entorno de ejecución, permitiendo que sean leídos y procesados en cálculos on-chain. Esto convierte a Irys en una capa de infraestructura de datos fundamental, más allá de un simple protocolo de almacenamiento.
Proceso de carga de datos: del envío del usuario al registro on-chain
La carga de datos en Irys se asemeja a una transacción en blockchain. Los usuarios empaquetan sus datos y los envían a la red, donde pasan al proceso on-chain.
El almacenamiento no es centralizado; los datos se dividen y distribuyen en varias particiones dentro de la red. Cada partición, con una capacidad aproximada de 16 TB, constituye la unidad básica de almacenamiento de Irys y favorece la escalabilidad y el control de costes.
A medida que los datos se escriben en los bloques, su estado queda registrado on-chain y pasa a las fases de verificación. Este proceso traza la ruta completa de escritura de datos y sienta las bases para su posterior validación y recuperación.
Fuente: irys.xyz
Mecanismo de verificación de datos: cómo Irys logra datos verificables (Proof of Storage / Availability)
La clave innovadora de Irys es incorporar la verificación de datos al mecanismo de consenso. Cada bloque valida transacciones y además prueba que los datos siguen presentes y accesibles.
Esto se logra mediante muestreo de datos y verificación de hash. La red solicita a los nodos que lean fragmentos de datos y realicen cálculos, lo que confirma el almacenamiento real y no solo la existencia simulada.
Irys introduce un mecanismo de minería de almacenamiento: los nodos deben leer y verificar bloques de datos de forma continua para participar en la generación de bloques. Así, la verificación de datos es parte central de la operativa de la red, no solo una función auxiliar.
Este diseño resuelve el reto principal del almacenamiento descentralizado: cómo confirmar la existencia de los datos sin necesidad de confianza.
Recuperación y consulta de datos: acceso, indexación e invocación en Irys
Una vez almacenados y verificados, los usuarios pueden consultar y recuperar los datos mediante identificadores. Los nodos de la red devuelven el contenido solicitado.
A diferencia del almacenamiento tradicional, Irys permite que los datos sean leídos y llamados directamente por aplicaciones on-chain. Los contratos inteligentes pueden ejecutar lógica basada en estos datos sin depender de API externas.
Esta estructura legible y computable convierte a Irys en una infraestructura robusta para aplicaciones Web3, especialmente las impulsadas por datos.
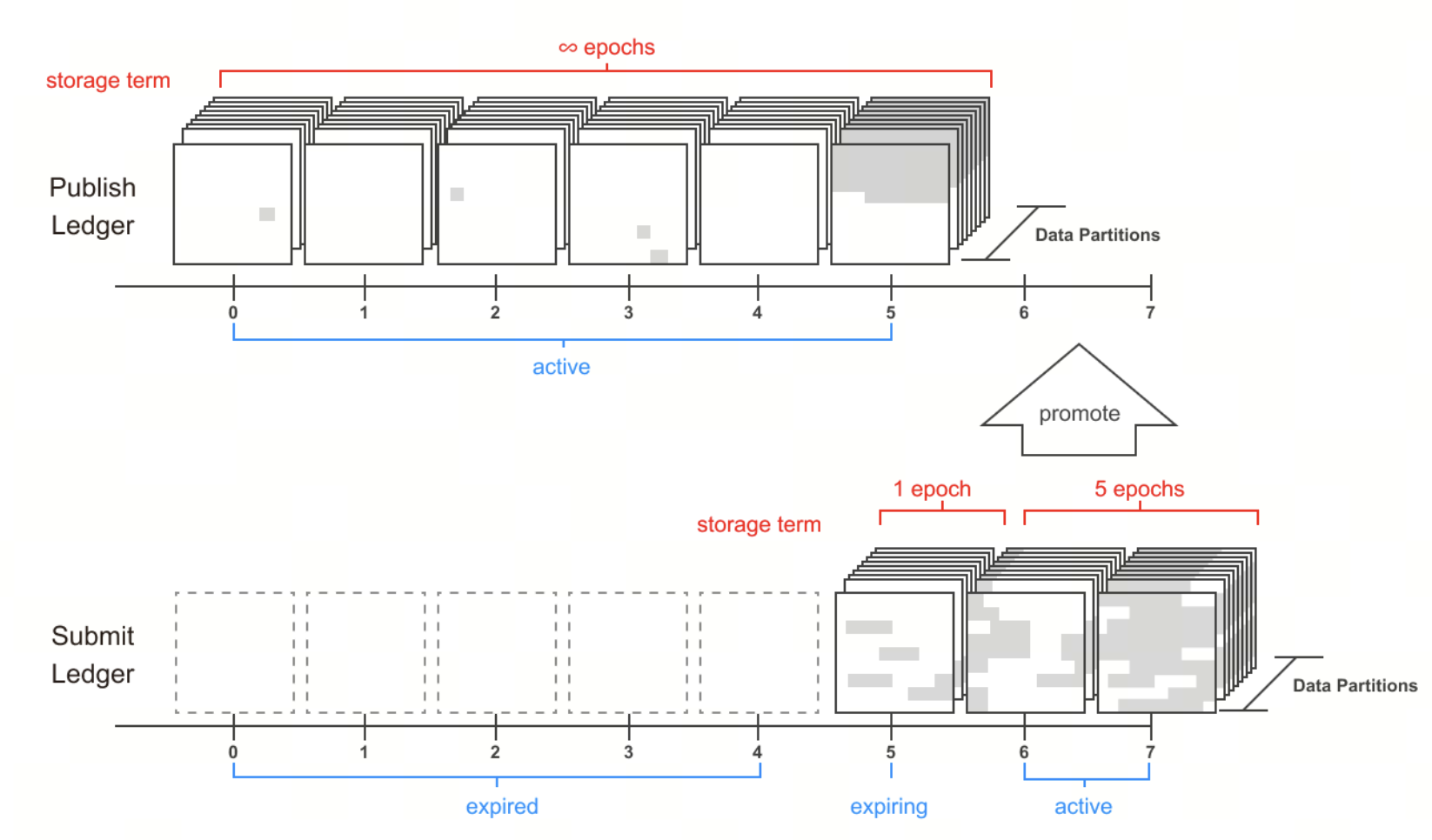
Garantizar la disponibilidad de los datos: nodos, consenso y ciclo de vida de las particiones
Irys garantiza la disponibilidad a largo plazo de los datos mediante el mecanismo Partition Lifecycle.
La red divide el almacenamiento en particiones de 16 TB, gestionadas mediante:
-
Partition Pledging: Los nodos ponen en staking tokens para participar en el almacenamiento
-
Partition Packing: Matrix Packing vincula los datos a la identidad de los nodos y evita ataques de replicación
-
Partition Mining: Los nodos leen y computan datos de forma continua para demostrar la existencia de los datos
-
Ledger Assignment: Los nodos con mejor rendimiento reciben más datos reales y mayores recompensas
Durante todo el ciclo de vida, los nodos deben demostrar su capacidad de almacenamiento o se arriesgan a perder recompensas y ser penalizados.
Si un nodo abandona la red, el sistema reasigna automáticamente los datos, evitando pérdidas por inactividad. Así, la disponibilidad de los datos es una característica inherente al sistema.
Ventajas y limitaciones del mecanismo de almacenamiento de Irys: verificabilidad, coste y rendimiento
La principal ventaja de Irys es la verificabilidad de los datos. La red prueba de forma continua la existencia de los datos, elimina la necesidad de confianza y permite aplicaciones altamente fiables.
La integración de datos y ejecución permite a las aplicaciones aprovechar los datos on-chain directamente, reduciendo la dependencia de sistemas externos. Esto resulta especialmente útil en DeFi, IA y escenarios similares.
No obstante, el sistema es complejo, implica particiones, verificación y consenso, y requiere recursos significativos de almacenamiento y cómputo.
Por ello, Irys está orientado a entornos que exigen alta credibilidad de los datos, no al simple almacenamiento de archivos.
Resumen
Al unificar almacenamiento, verificación y ejecución de datos, Irys crea una infraestructura de datos Web3 pionera. Su innovación es permitir que los datos existan, sean comprobables y participen en el cómputo.
Gracias a la partición y la verificación continua, Irys asegura la disponibilidad de los datos a largo plazo y minimiza la dependencia de sistemas externos. Esta arquitectura lo distingue de los protocolos tradicionales y lo posiciona como referente en capas de datos verificables.
Preguntas frecuentes
1. ¿Por qué los datos de Irys requieren verificación?
Porque en una red descentralizada no se puede depender de un solo nodo; se necesitan mecanismos de verificación para confirmar la existencia real de los datos.
2. ¿Qué es una partición?
Es la unidad fundamental de almacenamiento en Irys, utilizada para almacenar y verificar una cantidad definida de datos.
3. ¿Para qué sirve Matrix Packing?
Vincula los datos a los nodos y previene trampas por replicación de datos.
4. ¿Cómo evita Irys la pérdida de datos?
El almacenamiento distribuido y la reasignación de particiones garantizan la integridad de los datos incluso si los nodos abandonan la red.
5. ¿Cuál es la principal diferencia entre Irys y el almacenamiento tradicional?
El almacenamiento tradicional se centra en conservar los datos, mientras que Irys prioriza datos verificables y utilizables en el cómputo.








