Fuente: Cantidad de bits
El tercer día de la Semana del Open Source, DeepSeek reveló el “poder” detrás del entrenamiento de inferencia V3/R1.
DeepGEMM: Una biblioteca GEMM (Universal Matrix Multiplication) FP8 que admite operaciones de multiplicación de matrices expertas densas y mixtas (MoE).
Empecemos por entender brevemente qué es GEMM.
GEMM, es decir, la multiplicación de matrices general, es una operación básica en álgebra lineal, es un ‘frecuente’ en campos como el cálculo científico, el aprendizaje automático, el aprendizaje profundo, etc., y también es el núcleo de muchas tareas de cálculo de alto rendimiento.
Pero debido a que su cálculo suele ser bastante grande, la optimización del rendimiento de GEMM es crucial.
Y DeepGEMM, que DeepSeek ha abierto en esta ocasión, sigue manteniendo las características de “alto rendimiento + bajo costo”, con los siguientes puntos destacados:
- Alto rendimiento: En la GPU de la arquitectura Hopper, DeepGEMM puede lograr un rendimiento de hasta 1350+ FP8 TFLOPS.
Simplicidad: La lógica del núcleo es de solo unas 300 líneas de código, pero el rendimiento es mejor que el de un kernel afinado por expertos.
- Compilación Just-in-Time (JIT): Adopta un enfoque de compilación completamente just-in-time, lo que significa que puede generar código optimizado dinámicamente en tiempo de ejecución para adaptarse a diferentes hardware y tamaños de matriz.
- Sin dependencias pesadas: Esta biblioteca está diseñada para ser muy ligera, sin relaciones de dependencia complejas, lo que la hace fácil de implementar y utilizar.
- Soporta varios diseños de matrices: admite diseños de matrices densas y dos tipos de diseños MoE, lo que le permite adaptarse a diferentes escenarios de aplicación, incluido pero no limitado a modelos mixtos de expertos en el aprendizaje profundo.
En pocas palabras, DeepGEMM se utiliza principalmente para acelerar las operaciones de matriz en el aprendizaje profundo, especialmente en el entrenamiento e inferencia de modelos a gran escala. Es particularmente adecuado para escenarios que requieren recursos computacionales eficientes y puede mejorar significativamente la eficiencia del cálculo.
Muchos internautas están bastante ‘de acuerdo’ con esta fuente abierta, algunos comparan DeepGEMM con un superhéroe en el mundo de las matemáticas, creen que es más rápido que una calculadora rápida y más poderoso que una ecuación polinómica.
También se ha comparado el lanzamiento de DeepGEMM con la estabilización del estado cuántico en una nueva realidad, elogiando su compilación instantánea y limpia.
Claro… Algunas personas también están empezando a preocuparse por las acciones de Nvidia en sus manos…
!
Comprender profundamente DeepGEMM
DeepGEMM es una biblioteca creada específicamente para la multiplicación universal de matrices (GEMM) FP8 simple y eficiente con escalado de grano fino, que se deriva de DeepSeek V3.
Puede manejar tanto la multiplicación de matrices generales comunes como la multiplicación de matrices generales para la agrupación de MoE.
Esta biblioteca está escrita en CUDA, no es necesario compilar durante la instalación, ya que compilará todos los programas de núcleo en tiempo de ejecución a través de un módulo de compilación en tiempo real (JIT) liviano.
Actualmente, DeepGEMM solo es compatible con Hopper Tensor Core de NVIDIA.
Para resolver el problema de la falta de precisión en el cálculo acumulativo del núcleo del tensor FP8, se adopta el método de acumulación de dos niveles (mejora) del núcleo CUDA.
Aunque DeepGEMM se inspira en algunas ideas de CUTLASS y CuTe, no depende excesivamente de sus plantillas o cálculos algebraicos.
Por el contrario, esta biblioteca está diseñada de forma muy concisa, con solo una función de núcleo central y aproximadamente 300 líneas de código.
Esto lo convierte en un recurso conciso y fácil de entender para aprender técnicas de multiplicación y optimización de matrices FP8 bajo la arquitectura Hopper.
A pesar de su diseño ligero, el rendimiento de DeepGEMM iguala o supera a las bibliotecas de ajuste expertas para una variedad de formas de matriz.
Entonces, ¿qué pasa con el rendimiento?
El equipo utilizó NVCC 12.8 en el H800 para probar todas las formas que podrían usarse en la inferencia de DeepSeek-V3/R1 (incluido el relleno previo y la decodificación, pero sin paralelismo tensorial).
La siguiente imagen muestra el rendimiento de DeepGEMM común para modelos densos:
!
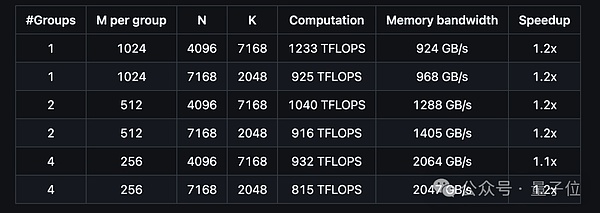
Según los resultados de la prueba, el rendimiento de cálculo de DeepGEMM** puede alcanzar hasta 1358 TFLOPS, y el ancho de banda de memoria puede alcanzar hasta 2668 GB/s.
En cuanto a la relación de aceleración, puede llegar hasta 2.7 veces en comparación con la implementación optimizada basada en CUTLASS 3.6.
Veamos el rendimiento de DeepGEMM en el soporte del modelo MoE con diseño contiguo.
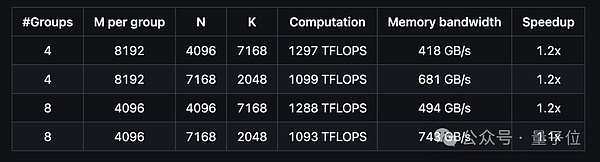
Y el rendimiento de admitir el diseño enmascarado del modelo MoE es el siguiente:
¿Cómo usarlo?
Para utilizar DeepGEMM, hay algunas dependencias que se deben tener en cuenta, entre las que se incluyen:
- Debe ser compatible con la GPU de la arquitectura Hopper, sm_90a.
- Python 3.8 and above.
- CUDA 12.3 and above (recommended 12.8).
- PyTorch 2.1及以上。
- CUTLASS 3.6 y superior
El código de desarrollo es el siguiente:
# Submodule must be clonedgit clone --recursive [email protected]:deepseek-ai/DeepGEMM.git# Cree enlaces simbólicos para (CUTLASS de terceros y CuTe) incluya directoriospython setup.py develop# Test JIT compilationpython tests/test_jit.py# Pruebe todos los implementos GEMM (normal, agrupados contiguos y agrupados enmascarados)python tests/test_core.py
El código de instalación es el siguiente:
python setup.py install
Después de los pasos anteriores, puede importar deep_gemm en su proyecto de Python.
En términos de interfaces, para DeepGEMM ordinario, se puede llamar a la función deep_gemm.gemm_fp8_fp8_bf16_nt y se admite el formato NT (LHS no transpuesto y RHS transpuesto).
En el caso de los DeepGEMM agrupados, m_grouped_gemm_fp8_fp8_bf16_nt_contiguous en el caso de un diseño continuo. En el caso del diseño de máscara, es m_grouped_gemm_fp8_fp8_bf16_nt_masked.
DeepGEMM también proporciona funciones de herramientas para configurar el número máximo de SM, obtener el tamaño de alineación de TMA, etc.; admite variables de entorno, como DG_NVCC_COMPILER, DG_JIT_DEBUG, etc.
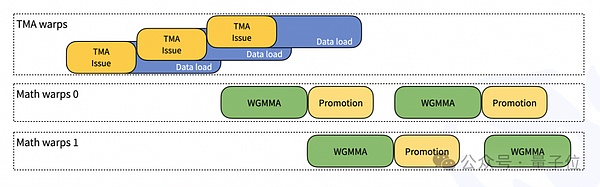
Además, el equipo de DeepSeek también proporciona varias formas de optimización, incluyendo:
Diseño JIT: Todos los kernels se compilan en tiempo de ejecución, no es necesario compilarlos en el momento de la instalación; Admite la selección dinámica del tamaño de bloque óptimo y la etapa de canalización.
- Escalado de granularidad fina: resuelve el problema de precisión FP8 mediante la acumulación de dos capas de núcleos CUDA; admite tamaños de bloque que no son potencias de 2, optimizando la utilización de SM.
FFMA SASS Interleaved: Mejora el rendimiento modificando el rendimiento y reutilizando los bits de las instrucciones SASS.
Los socios interesados pueden pinchar el enlace de GitHub al final del artículo para ver los detalles ~
Una cosa más
Las acciones de Nvidia … estos días Pozo… Sigue cayendo de nuevo:
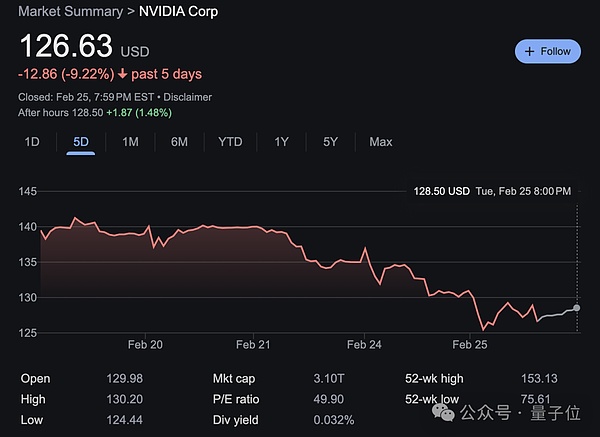
Sin embargo, en la madrugada del 27 de Beijing, también se dará a conocer el informe de rendimiento del cuarto trimestre del año fiscal 2025 de Nvidia. ¡Esperamos su desempeño!
