Les blockchains traditionnelles considèrent généralement les données comme un élément secondaire, séparant le stockage de l’exécution. Cette architecture rend difficile l’exploitation directe de données à grande échelle par les applications on-chain et accroît la dépendance aux services externes. Irys répond à ce défi structurel en intégrant le stockage, la vérification et l’exécution des données au sein d’un framework unifié.
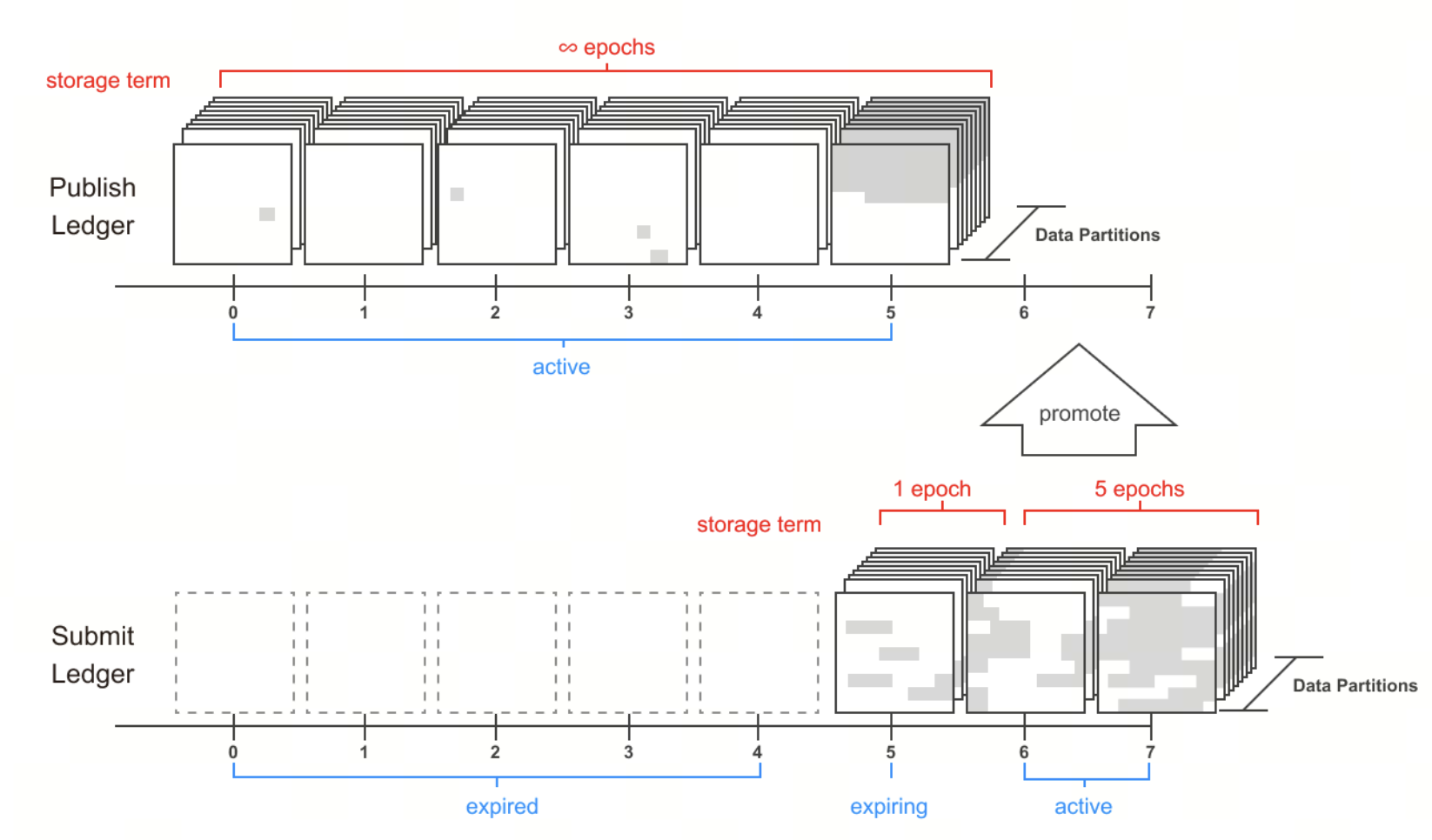
Pour comprendre Irys, il est essentiel de maîtriser le cycle de vie complet des données : comment elles sont téléchargées, vérifiées à l’échelle du réseau, puis consultées ou exploitées. Le mécanisme de stockage partitionné et de mining sous-jacent (Partition Lifecycle) est déterminant pour appréhender la vérifiabilité du protocole.
Principes fondamentaux du stockage de données Irys : couche de données décentralisée et stockage vérifiable
Irys adopte une architecture Datachain, intégrant les données directement dans le mécanisme de consensus de la blockchain. Contrairement au stockage traditionnel, les données ne sont pas simplement conservées : elles constituent un état on-chain vérifiable.
Dans ce modèle, chaque entrée de données doit être validée par le réseau comme étant réellement présente et accessible. Ce procédé transforme le stockage passif en existence prouvée, renforçant ainsi la confiance dans le système.
Par ailleurs, Irys associe les données à son environnement d’exécution, permettant à la fois la lecture et le traitement des données dans des calculs on-chain. Irys s’impose ainsi comme une couche d’infrastructure de données essentielle.
Processus de téléchargement des données : de la soumission utilisateur à l’enregistrement on-chain
Le téléchargement de données sur Irys fonctionne comme une transaction blockchain. Les utilisateurs préparent leurs données et les soumettent au réseau, puis celles-ci entrent dans le pipeline de traitement on-chain.
Les données ne sont pas centralisées : elles sont fragmentées et réparties sur plusieurs partitions de stockage du réseau. Chaque partition, d’une capacité d’environ 16 To, constitue une unité de base de la structure Irys, assurant évolutivité et maîtrise des coûts.
Lors de l’écriture dans les blocs, l’état des données est enregistré on-chain, puis soumis à des étapes de vérification successives. Ce processus définit le chemin complet d’écriture, fondement de la vérification et de la récupération ultérieures.
Source : irys.xyz
L’innovation majeure d’Irys est d’intégrer la vérification des données au cœur du consensus. Chaque bloc valide non seulement les transactions, mais prouve également que les données sont présentes et accessibles.
Ce mécanisme s’appuie sur l’échantillonnage des données et la vérification des hash. Le réseau sollicite en permanence les nœuds pour lire des fragments de données et effectuer des calculs, assurant ainsi un stockage réel et non simulé.
Irys introduit un mécanisme de mining de stockage : les nœuds doivent lire et vérifier continuellement les blocs de données pour participer à la création de blocs. Ainsi, la vérification des données devient une composante centrale du réseau.
Cette conception résout le défi fondamental du stockage décentralisé : prouver l’existence des données sans recourir à la confiance.
Récupération et requête des données : accès, indexation et invocation des données Irys
Une fois stockées et vérifiées, les données peuvent être consultées et récupérées par les utilisateurs à l’aide d’identifiants spécifiques. Les nœuds du réseau fournissent alors le contenu pertinent en fonction des requêtes.
À la différence du stockage traditionnel, Irys permet de lire les données et de les invoquer directement depuis des applications on-chain. Les Smart Contracts peuvent exécuter des logiques sur ces données sans dépendre d’API externes.
Cette architecture lisible et exploitable fait d’Irys une couche d’infrastructure robuste pour les applications Web3, en particulier celles axées sur la donnée.
Garantir la disponibilité des données : nœuds, consensus et cycle de vie des partitions
Irys assure la disponibilité à long terme des données grâce à son Partition Lifecycle.
Le réseau segmente le stockage en partitions de 16 To, gérées selon les étapes suivantes :
- Engagement de partition : les nœuds stake des tokens pour participer au stockage
- Emballage de partition : le Matrix Packing associe les données à l’identité des nœuds, évitant les attaques par réplication
- Mining de partition : les nœuds lisent et calculent en continu pour prouver l’existence des données
- Attribution du ledger : les nœuds les plus performants reçoivent de vraies données et bénéficient de rendements plus élevés
Tout au long du cycle, les nœuds doivent prouver leur capacité de stockage, sous peine de perdre leurs récompenses et d’être sanctionnés.
En cas de départ d’un nœud, le système réalloue automatiquement les données, garantissant l’intégrité même lors d’indisponibilités. Ce mécanisme fait de la disponibilité une propriété native du réseau.
L’avantage principal d’Irys est la vérifiabilité continue des données. Le réseau prouve en permanence leur existence, supprimant le besoin de confiance et permettant des applications à haute crédibilité.
L’intégration des données et de l’exécution offre aux applications la possibilité d’utiliser directement les données on-chain, réduisant la dépendance aux systèmes externes. Cela est particulièrement pertinent pour la DeFi, l’IA et des cas similaires.
En revanche, le système reste complexe, impliquant partitions, vérification et consensus, et requiert des ressources de stockage et de calcul importantes.
Irys s’adresse donc avant tout aux environnements exigeant une crédibilité maximale des données, plutôt qu’au simple stockage de fichiers.
Résumé
En unifiant stockage, vérification et exécution, Irys crée une nouvelle infrastructure de données Web3. Son innovation centrale : permettre aux données d’exister, d’être prouvées et de participer au calcul.
Grâce au partitionnement et à la vérification continue, Irys assure la disponibilité à long terme des données tout en limitant la dépendance aux systèmes externes. Cette architecture la distingue des protocoles de stockage classiques et positionne Irys comme référence des couches de données vérifiables.
FAQ
1. Pourquoi les données Irys doivent-elles être vérifiées ?
Parce que les réseaux décentralisés ne peuvent pas reposer sur un seul nœud ; il faut des mécanismes pour confirmer l’existence réelle des données.
2. Qu’est-ce qu’une partition ?
Une partition est l’unité de stockage de base d’Irys, utilisée pour stocker et vérifier une quantité définie de données.
3. Quel est l’objectif du Matrix Packing ?
Il associe les données aux nœuds, empêchant la triche par réplication.
4. Comment Irys évite-t-il la perte de données ?
Le stockage distribué et la réallocation des partitions garantissent l’intégrité, même lors du départ de nœuds.
5. Quelle est la principale différence entre Irys et le stockage traditionnel ?
Le stockage traditionnel vise à conserver les données, tandis qu’Irys privilégie des données vérifiables, utilisables dans la computation.







