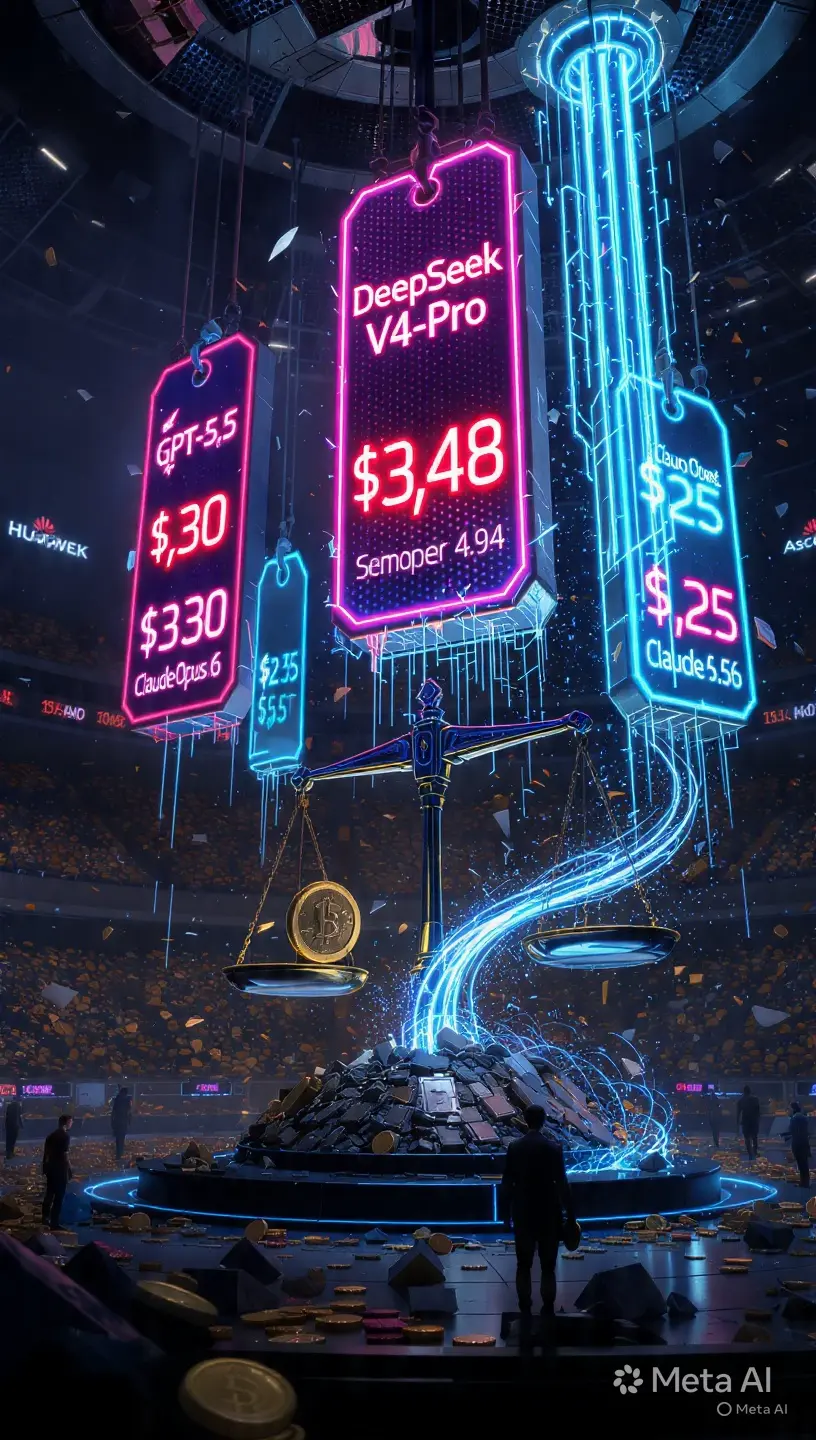#GateSquareDaily #Deepseek #AIPriceWar #AIAgents
The AI Price War Heats Up
DeepSeek’s V4 undercuts the market, and the ripple effects are already showing
A new front just opened in the AI race, and it’s not about benchmarks. It’s about price.
On April 24, 2026, Hangzhou-based DeepSeek released preview versions of its V4 model family: V4-Pro and V4-Flash. Both are open-weight, MIT-licensed, and support a 1-million-token context window. The headline, though, is cost.
1. How Aggressive Is the Cut?
DeepSeek’s API pricing resets the floor for frontier-class models:
• V4-Flash: $0.14 per million input tokens, $0.28 per million output tokens • V4-Pro: $1.74 per million input tokens, $3.48 per million output tokens
Compare that to current U.S. leaders: GPT-5.5 is priced at $5 input / $30 output per million tokens, while Claude Opus 4.6 runs $25 per million output tokens. Gemini 3.1 Pro sits at $2 input / $12 output.
In plain terms: V4-Pro is roughly one-seventh the cost of Claude Opus 4.6 and nearly one-ninth the cost of GPT-5.5 on output tokens. V4-Flash is 12.4x cheaper than Pro while trailing it by only 1.6 points on SWE-bench Verified. For developers, that’s the difference between a 4-month AI budget lasting 7 years at the same usage level.
The company said V4-Pro “matches leading models in several areas” and improves agent capabilities for multi-step tasks. Independent testing puts V4-Pro at 80.6% on SWE-bench Verified, within 0.2 points of Claude Opus 4.6. It leads on LiveCodeBench at 93.5%.
2. Why This Matters: Three Pressure Points
Adoption Could Accelerate
At $0.28 per million output tokens, V4-Flash makes high-volume use cases viable: document processing, codebase analysis, agent loops. Startups that were priced out of GPT-5-class reasoning can now run production workloads for 1/10th the cost. The 1M token context means entire code repos or legal filings fit in a single request.
Rivals Face Margin Squeeze
Western labs are already raising prices and limiting usage to manage demand. DeepSeek’s move forces a choice: cut prices and compress margins, or cede developer mindshare. The pricing gap is not 10% or 20% — it’s 7x to 9x on output. For companies building agentic workflows, token cost is now a line item, not a rounding error.
AI Narratives Gain Fuel, Including Crypto AI
Cheap inference changes the economics of AI agents. If you can run a 1.6T parameter model for $3.48 per million output tokens, on-chain agents, decentralized inference networks, and AI-token projects suddenly have a path to sustainable unit costs. V4 is MIT-licensed and open-weight, meaning anyone with GPUs can self-host. That removes vendor lock-in and aligns with crypto’s composability thesis.
Hardware is part of the story too. Huawei announced full support for V4 across its Ascend 950 chips the same day. DeepSeek validated the model on both Nvidia GPUs and Huawei Ascend NPUs. The company said Pro pricing could fall sharply once Ascend 950 supernodes deploy at scale in the second half of 2026. A domestic Chinese AI stack — models plus chips — lowers costs further and reduces reliance on U.S. hardware.
3. The Trade-offs
V4-Pro is not the best at everything. On SWE-bench Pro, which measures real-world software engineering, Opus 4.7 leads at 64.3% versus V4-Pro at 55.4%. On deep reasoning tasks, GPT-5.5 still holds an edge. DeepSeek acknowledges “constraints in high-end compute capacity” are limiting Pro throughput at launch.
And there’s regulatory context: the U.S. State Department warned globally about alleged Chinese distillation of U.S. AI models one day before V4 launched. OpenAI and Anthropic have accused DeepSeek of distilling their models. DeepSeek has not responded to those allegations.
4. What Happens Next
1. Enterprise pilots: Expect CFOs to re-run ROI models. If V4-Pro delivers 95% of the capability at 10% of the cost, “good enough” wins for many tasks. 2. Open-source momentum: With 1.6T parameters, MIT license, and Hugging Face weights, V4 becomes the largest open model available. Fine-tuning and private deployments get easier. 3. Hardware diversification: Full Ascend support signals China’s AI stack is maturing. If Huawei ships at volume, Chinese developers can build without Nvidia. 4. Pricing response: Watch OpenAI, Anthropic, and Google. Holding price while an open model hits 80.6% on SWE-bench at 1/9th the cost is not a stable equilibrium.
This is a price war, but it’s also a strategy shift. DeepSeek V4 doesn’t claim to beat GPT-5.5 or Claude Opus 4.7 on every benchmark. It claims to be close enough, open, and radically cheaper. For the last two years, the assumption was that frontier models require frontier budgets. V4 breaks that link.
If adoption follows price, then inference demand, agent usage, and AI-integrated apps — including crypto AI tokens — all expand. Competitors will have to respond on cost, not just capability. And the narrative that advanced AI must run on U.S. chips just got a counter-example.
The AI war is no longer just about who has the smartest model. It’s about who makes intelligence affordable.
The AI Price War Heats Up
DeepSeek’s V4 undercuts the market, and the ripple effects are already showing
A new front just opened in the AI race, and it’s not about benchmarks. It’s about price.
On April 24, 2026, Hangzhou-based DeepSeek released preview versions of its V4 model family: V4-Pro and V4-Flash. Both are open-weight, MIT-licensed, and support a 1-million-token context window. The headline, though, is cost.
1. How Aggressive Is the Cut?
DeepSeek’s API pricing resets the floor for frontier-class models:
• V4-Flash: $0.14 per million input tokens, $0.28 per million output tokens • V4-Pro: $1.74 per million input tokens, $3.48 per million output tokens
Compare that to current U.S. leaders: GPT-5.5 is priced at $5 input / $30 output per million tokens, while Claude Opus 4.6 runs $25 per million output tokens. Gemini 3.1 Pro sits at $2 input / $12 output.
In plain terms: V4-Pro is roughly one-seventh the cost of Claude Opus 4.6 and nearly one-ninth the cost of GPT-5.5 on output tokens. V4-Flash is 12.4x cheaper than Pro while trailing it by only 1.6 points on SWE-bench Verified. For developers, that’s the difference between a 4-month AI budget lasting 7 years at the same usage level.
The company said V4-Pro “matches leading models in several areas” and improves agent capabilities for multi-step tasks. Independent testing puts V4-Pro at 80.6% on SWE-bench Verified, within 0.2 points of Claude Opus 4.6. It leads on LiveCodeBench at 93.5%.
2. Why This Matters: Three Pressure Points
Adoption Could Accelerate
At $0.28 per million output tokens, V4-Flash makes high-volume use cases viable: document processing, codebase analysis, agent loops. Startups that were priced out of GPT-5-class reasoning can now run production workloads for 1/10th the cost. The 1M token context means entire code repos or legal filings fit in a single request.
Rivals Face Margin Squeeze
Western labs are already raising prices and limiting usage to manage demand. DeepSeek’s move forces a choice: cut prices and compress margins, or cede developer mindshare. The pricing gap is not 10% or 20% — it’s 7x to 9x on output. For companies building agentic workflows, token cost is now a line item, not a rounding error.
AI Narratives Gain Fuel, Including Crypto AI
Cheap inference changes the economics of AI agents. If you can run a 1.6T parameter model for $3.48 per million output tokens, on-chain agents, decentralized inference networks, and AI-token projects suddenly have a path to sustainable unit costs. V4 is MIT-licensed and open-weight, meaning anyone with GPUs can self-host. That removes vendor lock-in and aligns with crypto’s composability thesis.
Hardware is part of the story too. Huawei announced full support for V4 across its Ascend 950 chips the same day. DeepSeek validated the model on both Nvidia GPUs and Huawei Ascend NPUs. The company said Pro pricing could fall sharply once Ascend 950 supernodes deploy at scale in the second half of 2026. A domestic Chinese AI stack — models plus chips — lowers costs further and reduces reliance on U.S. hardware.
3. The Trade-offs
V4-Pro is not the best at everything. On SWE-bench Pro, which measures real-world software engineering, Opus 4.7 leads at 64.3% versus V4-Pro at 55.4%. On deep reasoning tasks, GPT-5.5 still holds an edge. DeepSeek acknowledges “constraints in high-end compute capacity” are limiting Pro throughput at launch.
And there’s regulatory context: the U.S. State Department warned globally about alleged Chinese distillation of U.S. AI models one day before V4 launched. OpenAI and Anthropic have accused DeepSeek of distilling their models. DeepSeek has not responded to those allegations.
4. What Happens Next
1. Enterprise pilots: Expect CFOs to re-run ROI models. If V4-Pro delivers 95% of the capability at 10% of the cost, “good enough” wins for many tasks. 2. Open-source momentum: With 1.6T parameters, MIT license, and Hugging Face weights, V4 becomes the largest open model available. Fine-tuning and private deployments get easier. 3. Hardware diversification: Full Ascend support signals China’s AI stack is maturing. If Huawei ships at volume, Chinese developers can build without Nvidia. 4. Pricing response: Watch OpenAI, Anthropic, and Google. Holding price while an open model hits 80.6% on SWE-bench at 1/9th the cost is not a stable equilibrium.
This is a price war, but it’s also a strategy shift. DeepSeek V4 doesn’t claim to beat GPT-5.5 or Claude Opus 4.7 on every benchmark. It claims to be close enough, open, and radically cheaper. For the last two years, the assumption was that frontier models require frontier budgets. V4 breaks that link.
If adoption follows price, then inference demand, agent usage, and AI-integrated apps — including crypto AI tokens — all expand. Competitors will have to respond on cost, not just capability. And the narrative that advanced AI must run on U.S. chips just got a counter-example.
The AI war is no longer just about who has the smartest model. It’s about who makes intelligence affordable.